

View in web for best experience
Happy April 27th, Industry 4.0!
Spring is in full swing.
The tulips are out. The grills are fired up. Somewhere a neighbor is mowing their lawn at 7am on a Saturday. And if you work in industrial tech, your inbox is full of Hannover Messe recaps, Kubernetes release notes, and the slowly dawning realization that the AI tools you've been betting on might have been quietly running in second gear for the last six weeks.
It's been a week in the world of Industry 4.0 infrastructure — and honestly, a pretty important one.
On one hand, the factory floor of the future showed up in Germany with humanoid robots doing real assembly work, AI agents reconfiguring machines through plain English, and digital twins running physics-grounded simulations in real time. The hype and the hardware are finally starting to meet. On the other hand, the Industry 4.0 Barometer 2026 reminded us that 46% of German manufacturers — the people who invented this concept — consider themselves laggards or feel like they've already missed the boat.
Meanwhile, in the infrastructure world, Kubernetes turned 12 and dropped its most grown-up release yet. Someone rewrote the entire thing in Rust, just to see if they could (they almost could). Grafana decided to give its AI assistant away for free to everyone — and then immediately told everyone not to use it too much. And Anthropic published one of the most transparent engineering postmortems we've seen from an AI lab, admitting that Claude Code had been quietly degraded for a month by three separate missteps — and that users weren't imagining it.
Here's what caught our attention this week:
The "Factory of the Future" Showed Up in Germany. Bring Your Skepticism.
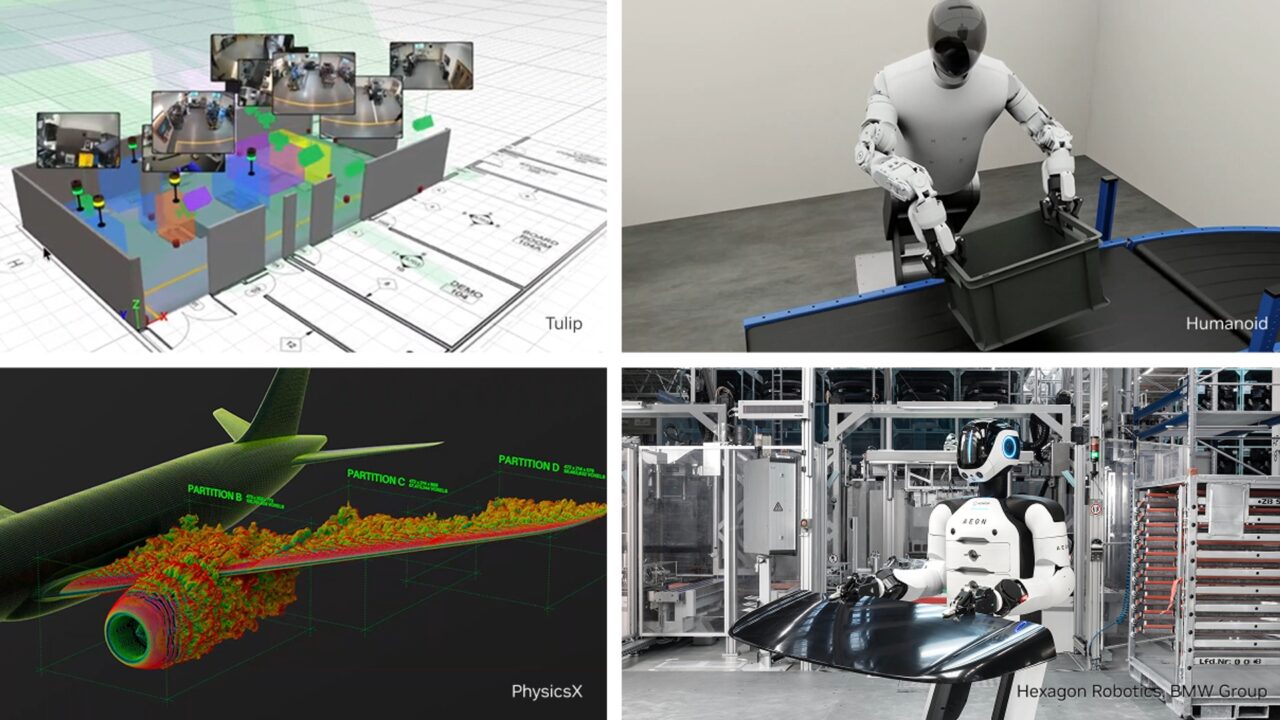
Hannover Messe 2026 wrapped up last week, and the press releases were — predictably — glorious.
Humanoid robots completing real assembly operations. AI agents configuring machines through natural conversation. Physics-grounded digital twins. NVIDIA, Siemens, ABB, SAP, and 3,000+ exhibitors all declaring that industrial AI has officially arrived.
Some of it was genuinely impressive. Some of it was a trade show floor.
What's actually worth paying attention to:
A few demos stood out from the marketing noise:
- Siemens ran a live shoe production line where AI didn't just recommend actions — it took them autonomously, with a packing robot and a humanoid working in tandem
- Hexagon Robotics' AEON humanoid is slated for actual assembly work at a BMW plant in Leipzig — not a concept, an imminent deployment
- SEW-EURODRIVE showed a machine configuration agent that works through plain-English dialog and — notably — doesn't rely on a conventional LLM, which matters for manufacturers wary of cloud dependency
- Around 15 companies showed humanoid robot systems, which is a meaningful signal about where investment is flowing
The part worth scrutinizing:
A recurring theme at Hannover was that AI will help manufacturers "do more with less" — specifically, less skilled labor. The framing: shrinking labor pools plus AI equals problem solved.
That's worth pushing back on.
We've seen this story play out badly in other industries already. Companies that moved aggressively to replace skilled workers with AI have frequently found that quality suffers in ways that are slow to surface and expensive to fix. Customer service is the most visible example — organizations that went "full AI" on support saw satisfaction scores crater before quietly walking it back. Manufacturing has even less margin for error. A bad recommendation from a customer service bot is annoying. A bad decision from an autonomous packing system on Line 3 can mean a recall.
The smarter framing — and the one the better Hannover demos actually reflected — is AI as an amplifier of skilled workers, not a replacement for them. Operators using real-time dashboards to adjust cutting parameters instead of running fixed programs blindly. Cobots handling the repetitive loading and unloading while experienced machinists focus on process optimization. AI flagging the anomaly, a human deciding what to do about it.
That's a meaningfully different vision than "the autonomous factory." And it's the one that's actually delivering results on production floors today.
The bottom line: AI on the factory floor isn't a binary choice between "automate everything" and "change nothing." The plants seeing real gains are threading a careful needle — using AI to sharpen what skilled workers do, not sidestep them. Before your leadership comes back from Hannover fired up about autonomous robots, ask the harder question: do we have the data foundation, the process discipline, and the experienced people to actually make this work? If the answer is "sort of" — you're not ready for the robot. You're ready for the groundwork.
NVIDIA at Hannover Messe 2026 → | Industry 4.0 Barometer 2026 →
Container Orchestration Just Got a Serious Upgrade — And Someone Rebuilt It From Scratch in Rust

If you've been following along with this newsletter for a while, you know we talk a lot about getting data off the plant floor and into systems where it can actually be used. Historians, SCADA, MES, cloud platforms — the whole stack. What we talk about less is the infrastructure layer underneath all of that. The plumbing that increasingly makes modern industrial software work.
That's where Kubernetes lives. And this week it had a big moment — two of them, actually.
First: what is Kubernetes, and why should you care?
Kubernetes (pronounced "koo-ber-NET-eez," often just called K8s) is the industry-standard system for deploying and managing software applications at scale. Think of it as the traffic controller for containerized software — it decides where applications run, keeps them healthy, restarts them when they crash, and scales them up or down based on demand.
Why does this matter for manufacturing? Because the software running your edge analytics, your AI inference models, your real-time data pipelines, and increasingly your MES integrations is being deployed in containers — and Kubernetes is what manages them. If your OT team is working with any modern industrial software vendor, there's a good chance Kubernetes is somewhere in that stack, even if nobody's told you that explicitly.
What's new in Kubernetes v1.36 "Haru":
Released April 22nd, v1.36 — nicknamed "Haru," the Japanese word for spring — ships 70 enhancements. Most of them are the kind of infrastructure maturity that doesn't make headlines but absolutely matters in production environments.
The ones worth flagging for industrial operations teams:
- User Namespaces hit stable (GA). This is a big security win. Previously, a process running as "root" inside a container had real power on the underlying host if the container was compromised. User Namespaces map that root to an unprivileged user on the host instead. For OT environments where container security is often an afterthought, this is a meaningful hardening feature that's now production-ready out of the box.
- Mutating Admission Policies go stable. Before this, enforcing rules across your cluster — like "every workload must have resource limits defined" — required running a separate webhook server. If that server crashed, pod creation could fail cluster-wide. Now that logic lives natively in Kubernetes as a versioned object. Simpler, more resilient, easier to audit. For regulated manufacturing environments, this matters.
- DRA (Dynamic Resource Allocation) improvements for AI/ML workloads. If you're running AI inference at the edge — computer vision for quality inspection, anomaly detection on sensor streams — DRA improvements mean Kubernetes can now more intelligently schedule those GPU-hungry workloads. Monitoring tools can also now reliably query per-pod hardware resource usage. Better visibility, better scheduling.
- Ingress NGINX officially retired. If you or your vendors are still using Ingress NGINX (and many are), it's time to migrate. No more security patches. No more updates. The Kubernetes community has moved on to Gateway API. If your industrial software vendor hasn't mentioned this to you yet — ask them about it.
The overall theme of v1.36: less friction, more operational sanity. It's a release built for people running Kubernetes in the real world, not just standing it up in a demo.
Now for the part that made the developer community do a double-take.
While the official v1.36 release was dropping, a developer named calfonso quietly published something remarkable on GitHub: Rusternetes — a complete, ground-up reimplementation of Kubernetes written entirely in Rust.
Not a wrapper. Not a fork. Not a simplified version. Every core component — API server, scheduler, controller manager, kubelet, kube-proxy — rewritten from scratch. 216,000+ lines of Rust. 3,100+ tests. Currently passing 90% of the official Kubernetes conformance test suite (398 out of 441 tests).
The project also includes something genuinely useful for industrial environments: a single-binary deployment mode where the entire cluster runs as one process with an embedded SQLite database. No containers required. No etcd cluster to manage. Your entire cluster state lives in a single file you can back up with a copy command.
Kubernetes v1.36 Release → | Rusternetes on GitHub →
Grafana Just Gave Away Its AI Assistant to Everyone. Its CFO Is Nervous.

If you run any kind of industrial monitoring stack — and if you're reading this newsletter, there's a good chance you do — Grafana is probably already in your life. It's the open-source dashboarding and observability platform that's become the default visualization layer for everything from Prometheus metrics to industrial historian data. Over 35 million users worldwide. Irish Rail uses it. LEGO uses it. Google uses it to build planet-scale dashboards.
This week at GrafanaCON 2026 in Barcelona, Grafana Labs dropped version 13 — and made an announcement that caught everyone off guard.
The headline: the AI assistant is now free. For everyone.
Grafana Assistant — previously available only to Grafana Cloud paying customers — is now available to open-source and on-premise users. That means if you're self-hosting Grafana on your plant network, you now have access to an AI agent that can help you build dashboards, write queries, troubleshoot data issues, and get answers from your observability data through a plain-English chat interface.
Grafana's CEO Raj Dutt announced this from the stage, then immediately added: "I'm honestly really excited — but also quite afraid. Please use it, but maybe not too much." His CFO, he noted, was worried.
That's either refreshingly honest or a mild red flag about the unit economics, depending on how charitable you're feeling.
What's new in Grafana 13:
- Suggested dashboards. Grafana now automatically surfaces pre-built dashboards tailored to your connected data sources. Less blank-page paralysis, faster time to insight.
- Git Sync is now GA. Manage your Grafana dashboards as version-controlled code, deployable through existing GitOps workflows. For environments with change management requirements, this is meaningful.
- Grafana Advisor. A new health check tool that runs diagnostics on your instance and flags outdated or insecure plugins — with AI-guided remediation built in.
- Loki gets a major rework. The log aggregation engine now reduces redundant writes and introduces stateless querying. Previously it could store the same log entry 2.3 times at petabyte scale. For teams generating high-volume log data from edge devices and control systems, this matters.
- IBM DB2 data source in public preview. If your plant runs legacy enterprise systems backed by DB2, you can now pull that data directly into Grafana alongside your OT telemetry.
Grafana 13 Release → | The Register's take →
When Your AI Tool Gets Quietly Worse and Nobody Tells You
If you've been using Claude Code over the past month and something felt off — you weren't imagining it.
Last Thursday, Anthropic published a rare, transparent engineering postmortem confirming that Claude Code had genuinely degraded for about six weeks. Not because the underlying model got worse. Because three separate product-layer changes compounded into something that looked like broad, mysterious regression across the whole tool. The API was unaffected throughout. If you were calling Claude directly, you felt nothing. If you were using Claude Code — you spent April fighting your tools.
What actually broke:
- March 4: Default reasoning effort quietly dropped from "high" to "medium" to reduce latency. Claude became less thorough on complex tasks. Anthropic later called it "a bad tradeoff." Reverted April 7.
- March 26: A caching bug meant to clear stale session context once instead cleared it on every turn. Claude became forgetful and repetitive mid-session. Fixed April 10.
- April 16: Two lines added to the system prompt to reduce verbosity — "keep text between tool calls to ≤25 words" — passed internal testing, then failed a coding eval by 3% that the standard suite never caught. Reverted April 20.
Because each change hit different users on different schedules, the aggregate looked like broad degradation that was hard to pin down and easy to dismiss as user error.
To their credit, Anthropic owned it fully. They reset usage limits for all subscribers, expanded internal dogfooding, and committed to tighter controls around prompt changes going forward.
Why this matters beyond Claude:
This is a story about what happens when you build operational workflows on top of AI tools. A few things worth sitting with:
Silent regressions are the hardest kind. The tool kept working — just worse. That's much harder to catch than an outage, and much easier to blame on yourself. And two lines of text in a system prompt caused a measurable quality drop — if you're building agentic workflows, treat your prompts like software. Version them. Test changes before shipping.
The vendors with the integrity to tell you when something went wrong are the ones worth building on. This postmortem, uncomfortable as it was, is a point in Anthropic's favor.
The bottom line: Claude Code is fixed as of April 20. But the incident is a useful reminder that AI tools require the same operational discipline as any other critical software dependency — monitoring, versioning, and healthy skepticism when something feels off.
Anthropic Engineering Postmortem →
Learning Lens
Where to Start in Digital Transformation for Manufacturers
![]()
One of the biggest takeaways from ProveIt! End users still don’t know where to start.
Not because they’re not capable. Not because they don’t care. Because what they’re being sold and what they actually need… are nowhere close to each other right now.
You’ve probably felt this. Vendors pushing solutions. Consultants talking about AI like it’s the answer to everything. And none of it lines up with what’s actually happening on your plant floor. That’s where the gap is.
That’s why we’re doing this workshop. Watch Walker explain it below—why we’re doing it, and what you should expect. Where to Start in Digital Transformation
This is a 2-day live workshop with Walker Reynolds and Dylan DuFresne.
Day 1 is the process:
Where do you actually start? How do you identify the right problems? What does a real strategy and architecture look like?
Day 2 is the application:
We walk through it step-by-step in a simulated Value Factory. Connect → Collect → Store → Analyze → Visualize → Find Patterns → Report → Solve
Not theory. What this actually looks like when you do it.
May 12–13 | Live Online
9:00am - 1pm CDT
Early Bird — $100 off through April 10
Use code START-EARLYBIRD
Learn more ->
Byte-Sized Brilliance
Chernobyl taught us a lesson about safety
Forty years ago yesterday — April 26, 1986 — Reactor No. 4 at the Chernobyl Nuclear Power Plant exploded during a safety test that had already failed three times.
The cause wasn't sabotage. It wasn't a freak accident. And it was the outcome of poor operations and safety from beginning to end.
On the night of the disaster, the crew disabled automatic shutdown mechanisms, bypassed emergency safety systems, and ran the reactor at dangerously low power levels for hours without coordinating with safety personnel. This was the product of a safety culture so hollowed out that operators didn't fully grasp what the rules were protecting them from. You can't respect a guardrail you don't know exists for a reason.
And when things started going wrong, there was nothing left to catch them. Every layer of protection that might have interrupted the chain of events had already been switched off — it wasn’t malicious, the goal was to complete a safety test, but the result was the worst nuclear disaster in history.
In manufacturing, production is king. Downtime costs money. Safety protocols can slow things down. There's a quiet, unspoken logic on many plant floors that goes: we'll be safe when we can afford to be. That logic is understandable. It's also how you end up with 30 workers dead in the first three months and 350,000 people evacuated from their homes.
Not all safety rules are bureaucratic red tape. Some are written in the language of things that already went wrong — on other floors, in other plants, in other countries. Someone stood where your operators are standing, made a decision that seemed reasonable under pressure, and paid for it. The rule exists so you don't have to learn the same lesson the same way. But rules only work if the people following them understand why they exist — not just that they exist.
Forty years later, the lesson is still the same: the most dangerous moment in any industrial operation is when confidence exceeds understanding. And the second most dangerous? When the people responsible for safety are never given the full picture of what they're actually protecting against.
Let us know how we're doing! https://forms.gle/zSXrKTK9BNZ3BrpXA

Responses