

Presented By

View in web for best experience
Tax Day is two days away. You're double-checking receipts, arguing with your accountant, and wondering how that one lunch receipt from October could possibly be "unsubstantiated."
Meanwhile, the federal government is doing some budgeting of its own. Specifically, proposing to cut $707 million from the agency that's supposed to protect your water treatment plant, your power grid, and your factory floor from state-sponsored hackers. You know — the same agency that this very week issued an urgent warning that Iranian hackers are actively disrupting PLCs across U.S. critical infrastructure.
The timing is... something.
But cyber threats aren't the only thing squeezing manufacturers right now. Tariffs have been reshaping supply chains for over a year, and the latest data shows the pain is getting harder to absorb — or pass along. And on the technology side, Kubernetes just dropped a release packed with features that finally treat AI/ML workloads like first-class citizens, while a deep dive into Postgres job queues is a reminder that sometimes the biggest threat to your system isn't a hacker — it's a forgotten database transaction quietly eating your performance alive.
Here's what caught our attention this week:
Your PLCs Are Under Attack. Your Federal Safety Net Is Shrinking. Now What?

Let's start with the headline you need to see: Iranian state-sponsored hackers are actively compromising Rockwell Automation PLCs across U.S. critical infrastructure — and causing real operational disruptions.
A joint advisory published last week by the FBI, CISA, NSA, EPA, Department of Energy, and U.S. Cyber Command warned that an Iranian-affiliated APT group has been exploiting internet-exposed PLCs since at least March 2026. The targets span water and wastewater systems, energy utilities, and government facilities. The victims experienced operational disruption and financial losses.
Here's how the attack works:
The attackers aren't using exotic zero-days. They're connecting to internet-exposed CompactLogix and Micro850 PLCs using legitimate Rockwell Automation software — specifically Studio 5000 Logix Designer — running from leased overseas infrastructure. Once connected, they're extracting project files, manipulating data displayed on HMI and SCADA screens, and deploying Dropbear (an SSH tool) for persistent remote access.
They're using your own programming software to talk to your own controllers because those controllers are sitting on the open internet.
Censys, a cybersecurity firm that scans for exposed devices, identified over 5,200 internet-exposed Rockwell Automation/Allen-Bradley PLCs following the advisory. And the agencies warned that other vendors — including Siemens — may also be targeted.
Why this is different from past warnings:
This isn't the first time we've heard about Iranian groups targeting industrial control systems. The CyberAv3ngers (linked to Iran's IRGC) compromised at least 75 Unitronics PLCs back in late 2023, mostly in water and wastewater systems. But this latest campaign marks a clear escalation — from espionage and probing to deliberate disruption. The agencies tied the escalation directly to ongoing hostilities between the U.S., Israel, and Iran.
The attackers aren't just reading your data. They're changing what your operators see on the screen. Think about that in your own facility: if someone manipulates the temperature reading on an HMI, or changes a setpoint value in a project file, how quickly does your team catch it? How would they even know?
Now here's where it gets worse.
The same week this advisory dropped, the White House proposed cutting CISA's budget by $707 million — roughly a 26% reduction. The proposal would eliminate approximately 1,000 positions, slash the National Risk Management Center's budget by 73%, cut $14 million from the Joint Cyber Defense Collaborative, and gut the Stakeholder Engagement Division by 62%. That last one is the team responsible for coordinating with state, local, and private-sector partners — which includes manufacturers.
CISA has already lost roughly a third of its workforce since the current administration took office. The agency still doesn't have a Senate-confirmed permanent director. And the $1.4 billion that is preserved focuses on federal network defense — not necessarily helping the private sector or critical infrastructure operators who don't fall under the federal umbrella.
One cybersecurity executive called the cuts "a strategic mistake at exactly the wrong moment." That might be an understatement.
Real-world scenario: You're a plant engineer running a mix of CompactLogix and Micro850 PLCs. Maybe some of those controllers were set up with remote access years ago — before OT security was a line item. Maybe a systems integrator left a port open for troubleshooting and it never got closed. That's exactly the kind of gap these attackers are exploiting. And going forward, there may be fewer federal resources available to tell you about it.
What you should do this week:
- Audit every internet-facing PLC and HMI immediately. If a controller is reachable from the public internet, it needs to come off today. Not next sprint. Today.
- Review CISA advisory AA26-097A for the specific TTPs (tactics, techniques, and procedures) and IOCs (indicators of compromise). Check your logs for connections on ports 44818, 2222, 102, 22, and 502 from unfamiliar IP addresses.
- Segment your OT network. PLCs and SCADA systems should sit behind firewalls with monitored boundaries between IT and OT. If your IT and OT networks are flat, this is your wake-up call.
- Enable multi-factor authentication on any system that touches your control layer. Disable default credentials and unused services.
- Contact Rockwell Automation's PSIRT (PSIRT@rockwellautomation.com) if you believe your organization may have been targeted. Review their security guidance documents PN1550 and SD1771.
- Don't wait for CISA to tell you. Build your own threat awareness pipeline. Follow ICS-CERT advisories, join your sector's ISAC (Information Sharing and Analysis Center), and subscribe to vendor security bulletins.
The bottom line: The federal government is simultaneously sounding the alarm and pulling back the firefighters. Whether you agree with the budget politics or not, the operational reality is clear — manufacturers need to treat OT cybersecurity as their own problem, not someone else's. The PLCs are already being hit. The question is whether yours are ready.
Read about the CISA budget proposal →
Tariffs, One Year In: The Numbers Are Getting Harder to Ignore

A year ago, tariffs felt like a storm you could wait out. Absorb the hit, hold pricing, see what happens. That strategy had an expiration date — and for most manufacturers, it's already passed.
A February 2026 survey from KPMG paints a picture that's hard to spin as anything other than painful. Eighty-two percent of companies report declining foreign sales since tariffs were first imposed. Sixty-one percent now say domestic sales are falling too. And the share of businesses passing more than half of their tariff costs on to customers has nearly tripled — from 13% last May to 34% today.
The consumer is now carrying the weight. And 55% of executives say they plan to raise prices another 15% within the next six months.
What's actually happening on the ground:
The current U.S. effective tariff rate sits at roughly 11% — the highest since 1943, according to Yale's Budget Lab. Steel and aluminum tariffs doubled to 50% last year. Autos, auto parts, copper, and semiconductors all carry significant levies. And pharma just got hit with tariffs up to 100% on branded imports (though exemptions and MFN deals will blunt the headline number for some).
For manufacturers, the math is brutal. You buy raw materials and components from global supply chains — steel, electronics, specialty chemicals, sensors, actuators — and every one of those inputs got more expensive. Meanwhile, the products you sell into export markets face retaliatory tariffs on the other end.
The Yale Budget Lab analysis found that while U.S. manufacturing output expands slightly in the long run (about 0.7%), those gains are more than offset by contractions in construction, mining, and agriculture. The net effect on the overall economy is persistently negative — about 0.1% smaller GDP, or roughly $27 billion annually.
Translation: manufacturing gets a small boost in isolation, but the ecosystem around it gets squeezed harder.
The reshoring reality check:
The stated goal of tariffs is to bring manufacturing back to U.S. soil. And there's real movement there — KPMG found that companies are actively executing supply chain changes, not just evaluating them. But the timeline is stretching, not shrinking. Sixty percent of companies say full reshoring would take one to three years, and the share expecting it to take more than three years has more than doubled (from 5% to 13%).
Why? Start with the obvious: high U.S. labor costs, the capital investment needed for new facilities, deeply integrated global supply chains, and — ironically — the tariffs themselves making equipment more expensive to buy. Factories take time to build, and the skilled workers to run them aren't materializing overnight.
But there's another layer that gets overlooked: the regulatory patchwork of actually building a new facility in the U.S. Permitting timelines, environmental reviews, zoning requirements — they vary wildly from state to state. Some states roll out the red carpet with fast-track permitting and tax incentives. Others bury you in 18 months of approvals before you pour a single foundation.
And here's the catch — the states with the cheapest land and least red tape aren't always the ones with the skilled workforce you need to actually run the facility. You can build a shiny new plant in a low-regulation state, but if you can't source controls engineers, maintenance techs, and automation specialists within a reasonable radius, you've just built a very expensive warehouse. Manufacturers considering reshoring have to weigh construction speed and cost against talent availability — and those two variables rarely line up neatly on the same map.
The bottom line: Tariffs aren't a temporary disruption anymore — they're the new operating environment. The manufacturers who treat them as a permanent variable in their cost models, sourcing strategies, and pricing decisions are going to navigate this better than the ones still waiting for the storm to pass. It's not passing.
Read the KPMG survey results →
Kubernetes 1.36: Why Your Factory's AI Workloads Just Got a Major Upgrade

If you're running — or planning to run — AI, machine learning, or high-performance computing workloads anywhere near your manufacturing operations, Kubernetes 1.36 deserves your attention. The release, scheduled for April 22nd, is packed with features that finally treat these resource-hungry, "everything needs to start at the same time" workloads as first-class citizens.
And if you just read "Kubernetes" and thought that's a DevOps thing, not a plant floor thing — hang tight. This is heading your way faster than you think.
Quick level-set: Kubernetes (K8s) is the system that orchestrates containerized applications — it decides what software runs where, how many copies to spin up, and what happens when something breaks. As manufacturers push AI inference, predictive maintenance, and digital twins closer to the production floor, K8s is increasingly the engine underneath.
The features that matter for industrial workloads:
Gang scheduling gets smarter. You need 8 GPUs for a distributed training job. Old Kubernetes scheduled them one at a time — find 7 but not the 8th, and you've got 7 expensive GPUs sitting idle. Kubernetes 1.36 introduces workload-aware preemption: the scheduler now treats grouped pods as a single unit. It either starts the whole job or waits until it can. No more zombie jobs burning compute while your quality inspection model half-launches.
GPU and hardware resource management grows up. The Dynamic Resource Allocation (DRA) system got a stack of improvements. Your application can now auto-discover GPU metadata from a simple JSON file inside the container instead of querying the API directly. You can ask the cluster "how many GPUs are free and where?" through a single API call — no more stitching together data from multiple sources. And if a GPU requires specific CPU and memory to function, the device can now declare those dependencies itself. The scheduler accounts for everything automatically instead of relying on you to manually specify every side requirement.
Topology-aware scheduling. Related pods can now be scheduled onto the same physical node or server rack. For latency-sensitive workloads — like a real-time inference model that needs to talk to a data preprocessing container with minimal delay — you tell the scheduler "keep these together" and it actually listens.
Scale to zero. The Horizontal Pod Autoscaler can now scale applications all the way down to zero replicas based on external metrics like message queue depth. No jobs? No pods. Work appears? They spin back up. For shift-based manufacturing workloads — scheduled analytics, periodic model retraining, batch quality reports — you stop paying for idle compute during off-hours.
The bigger picture for manufacturers:
Kubernetes 1.36 is a clear signal that the container orchestration world is building specifically for AI/ML and high-performance computing. That's exactly where manufacturing technology is heading — edge inference, distributed training, real-time digital twins, GPU-accelerated analytics.
You don't need to adopt Kubernetes tomorrow. But the tooling gap between K8s-native AI infrastructure and traditional deployments is widening with every release. If it's not on your technology radar yet, this release is a good reason to put it there.
The bottom line: This isn't just a DevOps upgrade — it's an industrial compute upgrade. Gang scheduling, GPU-aware resource management, topology-aware placement, and scale-to-zero all directly serve the workloads manufacturers are adopting right now. The orchestrator is catching up to the ambition.
Read the full Kubernetes 1.36 deep dive →
A Word from This Week's Sponsor
Your IIoT Database Worked Great in the POC. Will It Survive Production?
Here's a question most manufacturing teams don't ask until it's too late: what are the actual performance limits of your PostgreSQL database under a real IIoT workload?
Not the demo with 50 tags. The real thing — thousands of tags, ingesting 24/7, while dashboards and analytics compete for the same resources.
Doug Pagnutti at Tiger Data wrote an excellent breakdown of what he calls the IIoT PostgreSQL Performance Envelope — the intersection of three constraints that determine whether your database will hold up or quietly fall apart: ingest capacity, query speed, and storage costs. If you're running (or planning to run) PostgreSQL as the backbone of your historian, MES, or sensor data pipeline, this is required reading.
The central lesson: your database's behavior during a proof of concept almost never resembles its behavior at production scale. Understanding where the walls are before you hit them is the difference between a successful deployment and PoC purgatory.
Read: The IIoT PostgreSQL Performance Envelope →
The Silent Database Killer Lurking in Your Postgres Job Queues
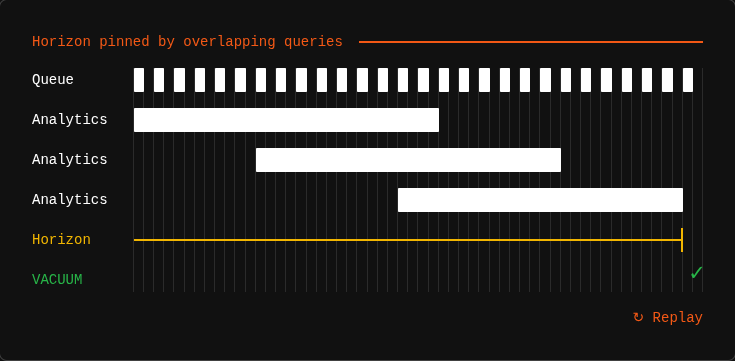
If you've ever heard the advice "just use Postgres" — for your job queues, your analytics, your time-series data, your everything — you're not alone. Postgres can genuinely handle a remarkable range of workloads. But there's a failure mode hiding inside Postgres-backed job queues that doesn't crash your system dramatically. It degrades it slowly, silently, and by the time you notice, your entire application is suffering.
A deep dive from PlanetScale this week resurfaced a problem first documented back in 2015 — and proved it's still alive and well in 2026.
Here's the setup:
A job queue in Postgres is simple. Rows get inserted, a worker picks them up, does the work, and deletes the row. The table stays roughly the same size while throughput is enormous. It's elegant, and it keeps your job state inside the same transaction as your application logic — no need to coordinate with an external message broker.
The problem isn't performance. Postgres can chew through tens of thousands of queue jobs per second. The problem is cleanup.
Dead tuples: the quiet mess.
When you delete a row in Postgres, it doesn't actually disappear. It gets marked as invisible to new transactions but physically remains on disk as a "dead tuple." A background process called autovacuum eventually comes along and reclaims that space.
This works great — until it doesn't.
The catch is that Postgres won't vacuum away any dead tuple that might still be visible to an active transaction. The oldest running transaction sets the cutoff — called the "MVCC horizon." Until that transaction finishes, every dead tuple newer than its snapshot gets retained. One analytics query that takes two minutes to complete pins the horizon for the full two minutes. And during those two minutes, dead tuples from your high-throughput job queue pile up with nowhere to go.
Why it matters for manufacturing:
If you're following the "just use Postgres" approach (and many manufacturers running MES, historian, or custom scheduling applications are), you likely have mixed workloads sharing a single database. Your fast job queue — processing work orders, triggering alerts, dispatching maintenance tasks — lives alongside slower analytics queries pulling shift reports or running quality trend analysis.
Real-world scenario: Your maintenance dispatch system processes hundreds of jobs per minute. Meanwhile, someone in quality engineering runs a 90-second query pulling defect trends for the last quarter. That query doesn't even touch the job queue table — but it pins the MVCC horizon for the entire database. Dead tuples from your job queue accumulate the entire time. Lock times creep up. Jobs that used to complete in 2 milliseconds start taking 30, then 100, then 300. No alert fires. Nothing "breaks." It just gets slower and slower until someone notices dispatch tickets are lagging.
And here's the nasty part: it's not just one long query that causes this. Multiple overlapping shorter queries can produce the same effect. Three analytics queries running 40 seconds each, staggered 20 seconds apart — none of them individually suspicious, but one is always active, so the horizon never advances. Autovacuum literally cannot do its job.
What the PlanetScale team found:
They recreated a 2015 benchmark that originally put Postgres into a death spiral within 15 minutes. On modern Postgres (version 18), the same workload survived longer — B-tree improvements and SKIP LOCKED have raised the floor significantly. But the dead tuple accumulation curve was still linear. The ceiling hasn't been removed, just raised. At higher throughput (800 jobs/second), the death spiral returned in full force.
The core mechanism is unchanged after a decade: if your MVCC horizon stays pinned, dead tuples accumulate, index scans slow down, and eventually your queue — and everything else in that database — degrades.
What you can do about it:
- Know your longest-running queries. Monitor
pg_stat_activityfor transactions that hold the MVCC horizon open. That 90-second analytics report might be fine in isolation — but if it overlaps with others, it's starving your vacuum. - Use
statement_timeoutandtransaction_timeout(available since Postgres 17) to put hard limits on how long any single query or transaction can run. They're blunt tools, but better than no guardrails. - Tune autovacuum aggressively for queue tables. Per-table settings like
autovacuum_vacuum_cost_delayandautovacuum_vacuum_scale_factorlet you tell Postgres "vacuum this table more often and more aggressively than everything else." - Separate your workloads where possible. If your analytics queries are the ones pinning the horizon, consider routing them to a read replica. Keep the primary clean for your transactional and queue workloads.
- Keep queue transactions short. The
FOR UPDATE SKIP LOCKEDpattern (grab a job, do the work, delete, commit) is the gold standard. The longer your transaction stays open, the longer it holds back vacuum. - Monitor dead tuple counts. Query
pg_stat_user_tablesand watchn_dead_tupfor your queue tables. If that number is climbing steadily instead of cycling up and down, your vacuum is losing the race.
The bottom line: The biggest threat to your Postgres job queue isn't a bad schema or slow hardware — it's an unrelated query on the other side of the database quietly preventing cleanup. In a "just use Postgres" world, your job queue is only as healthy as the worst-behaved workload sharing its database. Monitor accordingly.
Read the full PlanetScale deep dive →
Learning Lens
Where to Start in Digital Transformation for Manufacturers
![]()
One of the biggest takeaways from ProveIt! End users still don’t know where to start.
Not because they’re not capable. Not because they don’t care. Because what they’re being sold and what they actually need… are nowhere close to each other right now.
You’ve probably felt this. Vendors pushing solutions. Consultants talking about AI like it’s the answer to everything. And none of it lines up with what’s actually happening on your plant floor. That’s where the gap is.
That’s why we’re doing this workshop. Watch Walker explain it below—why we’re doing it, and what you should expect. Where to Start in Digital Transformation
This is a 2-day live workshop with Walker Reynolds and Dylan DuFresne.
Day 1 is the process:
Where do you actually start? How do you identify the right problems? What does a real strategy and architecture look like?
Day 2 is the application:
We walk through it step-by-step in a simulated Value Factory. Connect → Collect → Store → Analyze → Visualize → Find Patterns → Report → Solve
Not theory. What this actually looks like when you do it.
May 12–13 | Live Online
9:00am - 1pm CDT
Learn more ->
Byte-Sized Brilliance
The Modbus protocol — the communication standard running on a significant portion of the world's industrial control systems, including power grids, water treatment facilities, and factory floors — was created in 1979. By Modicon. For talking to PLCs.
That's 47 years ago. Modbus predates the IBM PC. It predates Windows. It predates the World Wide Web by over a decade. It predates the adoption of TCP/IP as the networking standard. It was designed for closed, air-gapped networks where "security" meant a locked door on the electrical room.
And here's the thing: Modbus still has no built-in authentication or encryption. None. Any device that can reach a Modbus endpoint can read from it. Many can write to it. There's no username, no password, no handshake. If you can see it, you can talk to it.
According to Comparitech, researchers recently found 179 internet-exposed Modbus devices across 20 countries — including one tied to a national railway network and two connected to power grid infrastructure. Bitsight reported that the total number of internet-exposed ICS devices globally climbed past 180,000 and is trending toward 200,000. And according to Dragos, fewer than 10% of OT networks worldwide have any visibility or monitoring in place.
We put locks on our email accounts, two-factor on our Instagram, and biometric authentication on our phones. Meanwhile, the protocol controlling physical infrastructure that serves millions of people was designed before floppy disks were standard — and we never bothered to give it a password.
Sleep well.
Let us know how we're doing! https://forms.gle/zSXrKTK9BNZ3BrpXA

Responses