

Presented By
![]()
View in web for best experience
Happy day-after-Easter. Hope you got some rest, some good food, and maybe hid a few eggs for the kids.
Here's the thing about the Easter story that's always stuck with us from a security perspective (stay with us here): the biggest threat to Jesus wasn't Rome. It was Judas — someone inside the inner circle, someone trusted, someone with access.
That's basically the theme of this entire week in cybersecurity.
A North Korean hacking group didn't break into anything. They socially engineered a trusted maintainer of one of the most downloaded packages on the internet — and had a remote access trojan deployed before anyone noticed. Anthropic didn't get hacked. They accidentally shipped 512,000 lines of their own source code to the public npm registry — and attackers had credential-stealing malware disguised as the leak within hours. Oracle didn't have a data breach. They sent a 6 AM email to 30,000 employees telling them today was their last day.
The threat didn't come from outside the walls. It came from inside the house — from the dependencies we trust, the tools we build with, and the companies we work for.
Your multi-factor authentication? A new phishing technique figured out how to waltz right past that too. We'll save that one for next week.
But it's not all betrayal and existential dread. We've also got a piece on a humble little database that's been quietly hiding superpowers in plain sight — and there's a decent chance it's already running on every device in your plant.
Here's what caught our attention this week:
The Axios Attack — When North Korea Comes for Your npm Install
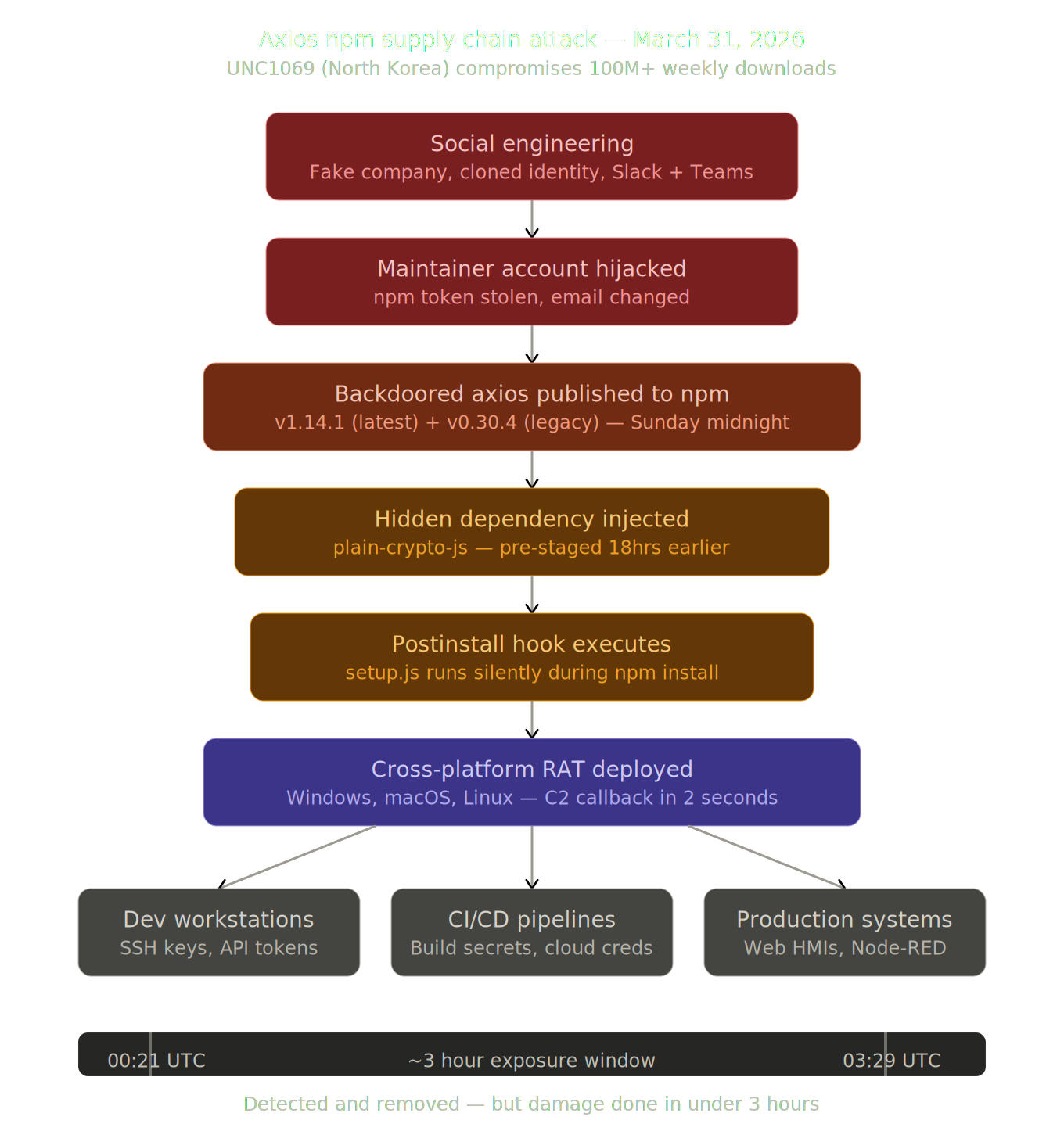
A North Korean hacking group just compromised one of the most popular packages on the internet. If your plant runs anything built with JavaScript, pay attention.
On March 31st, a threat group tracked as UNC1069 pulled off one of the most sophisticated software supply chain attacks ever documented. Their target? Axios — a JavaScript HTTP client library that handles roughly 100 million downloads per week. If you've ever used a web-based dashboard, a Node-RED flow, or a modern HMI built on web technologies, there's a good chance Axios is somewhere in the stack.
Here's the thing — they didn't find a vulnerability. They didn't write an exploit. They made a friend.
How it went down:
The attackers identified Jason Saayman, the lead maintainer of the Axios project, and built an elaborate social engineering operation specifically tailored to him. They cloned a real company founder's identity, created a convincing Slack workspace branded to match the company, populated it with fake channels sharing real LinkedIn posts, and invited Saayman in. Then they scheduled a Microsoft Teams meeting.
Somewhere in that process, they compromised his npm access token. And with that token, they published two backdoored versions of Axios — v1.14.1 and v0.30.4 — at roughly midnight UTC on a Sunday night. Maximum time before anyone would notice. Maximum damage.
What the malware actually did:
The poisoned versions didn't modify a single line of Axios source code. Instead, they injected a new dependency called plain-crypto-js — a package that had been quietly pre-staged 18 hours earlier with a clean "version history" to avoid triggering new-package alarms. When your system ran npm install, the dependency's postinstall hook silently downloaded and executed a cross-platform Remote Access Trojan (RAT) — one version each for Windows, macOS, and Linux.
Within two seconds of npm install, the malware was already calling home to the attacker's command-and-control server. Before npm had even finished resolving the rest of your dependencies.
The backdoored packages were live for approximately three hours before they were detected and pulled. In that window, Huntress observed at least 135 endpoints across all operating systems contacting the attacker's C2 infrastructure — and that's just within their customer base.
Why this matters for manufacturing:
"But we don't write JavaScript on the factory floor." Maybe not directly. But here's where it gets real:
- Node-RED, one of the most popular tools for wiring together IIoT flows, runs on Node.js and uses npm packages
- Web-based HMIs and dashboards — whether custom-built or from vendors like Ignition's web modules — often depend on JavaScript libraries
- CI/CD pipelines that build and deploy edge software to your plant floor pull packages from npm during build
- SCADA web interfaces and historian frontends increasingly use modern JavaScript frameworks that transitively depend on libraries like Axios
If any of those systems ran an npm install during that three-hour window on March 31st, you need to treat them as compromised. Full stop.
What to do right now:
- Check your lockfiles for
axios@1.14.1oraxios@0.30.4. If either is present, assume compromise - Pin your dependencies. Stop using floating version ranges (the
^or~in your package.json). Pin to exact versions - Rotate everything. If a compromised version ran on any machine, rotate all credentials that machine had access to — npm tokens, API keys, SSH keys, cloud credentials, everything in your
.envfiles - Block the C2 domain
sfrclak[.]comat your firewall - Audit your CI/CD pipelines for any runs between March 31 00:21 UTC and 03:29 UTC
The bottom line: The most popular package in your dependency tree just became the attack vector. Supply chain security isn't an abstract concept anymore — it's the thing standing between a North Korean hacking group and your development environment. If you're building anything that touches npm, your dependency hygiene just became a plant-floor safety issue.
Read the full Google Threat Intelligence analysis →
Oracle Cuts 30,000 Jobs — And the Lesson Isn't About Oracle

The enterprise software giant just eliminated roughly 18% of its workforce in a single morning. What it tells us about where the industry is headed matters more than the layoffs themselves.
If you woke up on March 31st and checked your email at 6 AM, you either found Easter weekend leftovers in your inbox or a message from Oracle that read: "We have made the decision to eliminate your role as part of a broader organisational change. As a result, today is your last working day."
No meeting. No transition period. Today is your last day. For an estimated 30,000 people worldwide — roughly 12,000 of them in India — that was Tuesday morning.
What happened:
Oracle is in the middle of an aggressive pivot toward AI infrastructure. The company announced plans earlier this year to raise $50 billion in debt and equity to build out data center capacity for AI workloads. Their remaining performance obligations jumped 359% to $455 billion following a deal with OpenAI worth over $300 billion.
That's the growth side. The other side? Barclays analysts noted the company's workforce is "less productive compared to the average." TD Cowen estimated that cutting 20,000 to 30,000 employees could free up $8 billion to $10 billion in incremental free cash flow.
So Oracle did the math. And 30,000 people got a 6 AM email.
Why this matters for manufacturing:
Here's the thing — this isn't just an Oracle story. This is the story of every enterprise software vendor your plant depends on. Microsoft, Amazon, Meta, and Atlassian have all run variations of this same playbook in the past 60 days: cut headcount in execution and support roles, redirect that cash into AI infrastructure, hire smaller specialized teams, and tell investors that AI-driven efficiency will more than compensate.
But let's pump the brakes for a second.
There's a version of this story where "AI" is doing a lot of heavy lifting as a justification. Not every company cutting jobs is doing it because AI has genuinely replaced those roles. Some of these layoffs were coming regardless — bloated headcount from the 2020-2021 hiring binge, margin pressure from rising interest rates, investors demanding profitability over growth. Slapping "AI transformation" on a cost-cutting exercise makes it sound like a strategy instead of a correction.
And here's the part nobody in the C-suite wants to talk about: the companies that have already made this pivot aren't exactly shipping better products. Windows 11 is the poster child — Microsoft has been aggressively integrating AI across everything while simultaneously delivering an operating system that most enterprise IT teams actively avoid upgrading to. Copilot gets bolted onto every surface. Actual reliability and user experience? Still waiting.
Google's search results have gotten measurably worse as they've prioritized AI-generated answers over actual links. Salesforce has been on a similar AI-everything push while its core platform gets more bloated and harder to administer. The pattern is consistent: companies announce AI pivots, cut the people who kept the core product stable, and then act surprised when the core product gets worse.
So what should manufacturing operations leaders actually do?
1. Your vendor's support team might be next. If you're running Oracle ERP, Oracle Cloud, or any enterprise platform from a company going through this kind of restructuring — expect support response times to get worse before they get better. The people who knew your implementation are the "execution roles" being eliminated. Document your configurations. Build internal knowledge bases. Don't assume your vendor's institutional knowledge will survive the next round of cuts.
2. The talent is about to hit the market. Thirty thousand experienced enterprise software professionals just became available. If you've been struggling to hire people who understand ERP systems, database administration, or cloud infrastructure — this is your window. These aren't junior developers. Many have decades of experience with systems that are probably running in your plant right now.
3. Be skeptical of your own vendors' AI pitches. When your ERP vendor shows up next quarter talking about "AI-native workflows" and "agentic automation," ask the uncomfortable question: is this replacing a feature that worked fine before, or is this solving an actual problem? The manufacturing floor doesn't need AI for AI's sake. It needs systems that are reliable, well-supported, and actually work. If your vendor is cutting the people who ensure that reliability to fund AI features you didn't ask for — that's not innovation. That's a red flag.
The uncomfortable question:
Oracle didn't lay off 30,000 people because it's failing. Its stock went up 6% the day the cuts were announced. But stock price and product quality are two very different things, and they often move in opposite directions during "transformation" periods.
The ISM Manufacturing PMI hit 52.7 in March — third straight month of expansion. But the employment sub-index has contracted 30 of the last 31 months. Production is up. Headcount is not. That same divergence is playing out at Oracle, at Microsoft, and eventually at the vendors who sell to your plant.
The bottom line: Oracle's layoffs aren't just a cost-cutting story with an AI label slapped on it — but they're not purely an AI story either. The truth is somewhere in between, and the manufacturing professionals who see through the narrative will be better positioned than those who take the "AI transformation" pitch at face value. Either way, now is the time to build internal resilience — because the person who knew your system best might have gotten a 6 AM email last Tuesday.
The Claude Code Disaster — A Leak, a Vulnerability, and Malware in One Week

Anthropic accidentally published its own source code. Within days, researchers found a critical vulnerability, and attackers were distributing credential-stealing malware disguised as the leak. It's a masterclass in how fast things go sideways.
If you wanted to design a worst-case scenario for software supply chain security, you'd be hard-pressed to beat what happened to Anthropic last week. What started as a packaging mistake cascaded into a full-blown security incident with at least three distinct layers of fallout — each one worse than the last.
Let's walk through it.
Layer 1: The accidental leak
On March 31st, Anthropic pushed version 2.1.88 of Claude Code — their AI-powered command-line coding tool — to npm (the same package registry involved in the Axios attack we just covered). The update included something that should never have been there: a 59.8 MB JavaScript source map file.
Source maps are debugging tools that translate compiled, minified code back into human-readable source. They're meant for development environments. This one contained 512,000 lines of unobfuscated TypeScript across 1,906 files — essentially the entire client-side codebase for Claude Code.
By 4:23 AM ET, security researcher Chaofan Shou spotted it and posted a download link on X. His post racked up over 28 million views. Within hours, the code was mirrored on GitHub, where it eventually collected 84,000+ stars and 82,000+ forks.
What was exposed: The complete agent orchestration logic, permission systems, tool execution framework, memory architecture, 44 unreleased feature flags (20+ not yet shipped), internal model codenames, and security-related internals including OAuth flows and telemetry. Not exposed: model weights, safety pipelines, or user data.
How did this happen? Bun, the JavaScript bundler Anthropic uses, generates source maps by default. A single missing exclusion rule in a build configuration file. That's it. One line of config, and one of the most significant AI code exposures in history.
Layer 2: The critical vulnerability
With 512,000 lines of source code now public, security researchers went to work. Adversa AI's red team found something alarming — a permission bypass vulnerability, now tracked as CVE-2026-21852.
Here's how Claude Code's permission system is supposed to work: commands go through allow rules (auto-approve), deny rules (hard-block), and ask rules (always prompt the user). It's a sensible design.
But Anthropic built in a safeguard to prevent the UI from freezing when handling complex composite commands — if a pipeline contains more than 50 subcommands, the system stops analyzing each one individually and just prompts the user to approve the whole batch.
The problem? A malicious CLAUDE.md configuration file (which Claude Code reads automatically when you open a repository) could use prompt injection to make the AI generate a pipeline with 51+ subcommands that look like a legitimate build process. When that happens, all deny rules, security validators, and command injection detection get skipped entirely. The 51st command could exfiltrate your SSH keys, AWS credentials, GitHub tokens, or anything else on your machine — and you'd see nothing but what looks like a routine build step.
Think about that in manufacturing terms. An engineer clones what looks like a legitimate repository — maybe a vendor's PLC configuration tool, maybe an open-source OPC-UA library. The repo contains a crafted CLAUDE.md file. The engineer runs Claude Code against it. Fifty steps later, every credential on that engineering workstation is on its way to an attacker's server.
Layer 3: The malware
This is where it gets ugly. Within hours of the leak going public, threat actors created fake GitHub repositories claiming to contain the leaked Claude Code source — optimized for SEO so they appeared near the top of Google results for "leaked Claude Code."
Zscaler's ThreatLabz team found a repository by user "idbzoomh" that advertised "unlocked enterprise features" and no message limits. Users who downloaded the 7-Zip archive found a Rust-based executable named ClaudeCode_x64.exe. Running it deployed Vidar (an infostealer that harvests account credentials, credit card data, and browser history) and GhostSocks (which turns infected machines into proxy infrastructure for further attacks).
The repository had 793 forks and 564 stars before it was flagged. At least two trojanized repos remained live on GitHub days after discovery.
And there's a fourth layer we haven't even mentioned: because the leak happened on March 31st — the same day as the Axios compromise — anyone who installed or updated Claude Code via npm during the three-hour Axios attack window may have also pulled the trojanized Axios dependency containing the North Korean RAT. Two completely separate supply chain compromises, hitting the same package registry, on the same day.
Why this matters for manufacturing:
AI coding tools are rapidly entering industrial software development workflows. Engineers are using Claude Code, GitHub Copilot, and similar tools to write PLC logic, configure SCADA systems, develop edge applications, and automate deployment pipelines. This incident reveals three risks that aren't going away:
- AI tools execute commands on your behalf with broad access. Claude Code can edit files, run shell commands, and manage git workflows. A permission bypass means an attacker can weaponize the tool against its own user
- The "helpful repository" is now an attack vector. Any repo with a crafted configuration file can potentially hijack an AI coding agent. This isn't limited to Claude Code — any AI tool that reads project-level config files is susceptible to similar attacks
- Curiosity is a vulnerability. Tens of thousands of people downloaded what they thought was leaked source code and ran executables from untrusted GitHub repos. Developers are not immune to social engineering, especially when the lure is something genuinely interesting
What to do:
- If you use Claude Code, update past version 2.1.88 immediately and rotate your API keys
- If you installed via npm on March 31st between 00:21 and 03:29 UTC, check for the malicious Axios dependency too
- Never run executables from "leaked source code" repositories. If it didn't come from the vendor's official channel, treat it as hostile
- Audit the
CLAUDE.mdfile in any repository before pointing an AI coding tool at it - Consider isolating AI coding tools in sandboxed environments, especially when working with untrusted codebases
The bottom line: One missed config line in a build file exposed half a million lines of source code. Within a week, that single mistake spawned a CVE, a malware campaign, and a supply chain collision with a completely separate North Korean operation. If you're using AI coding tools in your development workflow — and increasingly, industrial teams are — this is your wake-up call. The tools are powerful. The blast radius when something goes wrong is enormous.
Read the SecurityWeek analysis → Read The Register's coverage of the trojanized repos →
A Word from This Week's Sponsor
![]()
Manufacturers don’t need more disconnected tools. They need a better way to unify data, applications, and operations.
Fuuz is an AI-driven Industrial Intelligence Platform that helps manufacturers connect siloed systems, contextualize data, and turn that data into action. With a cloud-native architecture, edge capabilities, and a low-code/no-code environment, Fuuz makes it easier to build and scale industrial applications for MES, WMS, CMMS, and more.
From data modeling and API generation to real-time flows and application design, Fuuz gives manufacturers the tools to reduce complexity, improve visibility, and create more connected, resilient operations.
Design your solution today: fuuz.com/contact-us
Learn more: fuuz.com
Modern SQLite — The Database Hiding Superpowers in Plain Sight

You probably think of SQLite as that lightweight thing your phone uses. Turns out, it's been quietly accumulating features that make it genuinely useful for industrial applications — and it might already be running everywhere in your plant.
After three articles about things going catastrophically wrong, let's talk about something that's been going quietly, stubbornly right for 26 years.
SQLite is the most deployed database in the world. It's not even close. It runs on every iPhone, every Android device, every Mac, every Windows 10/11 machine, every major web browser, and inside countless embedded systems. If you have a device in your plant with a screen and a processor, there's a very good chance SQLite is already on it.
Most people think of it as a toy — something you use for prototyping or phone apps before you graduate to a "real" database like PostgreSQL or SQL Server. But modern SQLite has been picking up features that make that reputation seriously outdated. If you're an engineer building edge applications, local-first tools, or lightweight data collection systems on the plant floor, this is worth ten minutes of your time.
Feature 1: STRICT tables — finally, real type enforcement
SQLite has always been famous (or infamous) for its flexible typing. You could shove a string into an integer column and SQLite would just shrug and store it. Fun for prototyping. Terrifying for production.
Modern SQLite adds STRICT tables that enforce type constraints at insert time, much closer to how PostgreSQL behaves:
CREATE TABLE sensor_readings (
id INTEGER PRIMARY KEY,
sensor_id TEXT NOT NULL,
temperature REAL NOT NULL,
timestamp TEXT NOT NULL
) STRICT;Try to insert a string where a REAL belongs? Rejected. This one keyword eliminates an entire class of subtle data quality bugs — the kind that don't show up until your historian is full of garbage values and someone's trying to figure out why their trend chart looks wrong.
Feature 2: JSON support — structured and semi-structured in one place
Here's where it gets interesting for IIoT. SQLite ships with a JSON extension that lets you store and query JSON documents alongside your relational data.
Why this matters on the factory floor: Your MQTT messages, your REST API payloads from edge devices, your OPC-UA node attribute dumps — they all come in as JSON. Instead of parsing that JSON in your application code and mapping it to a rigid schema, you can store the raw payload and query it directly:
SELECT
json_extract(payload, '$.device_id') AS device,
json_extract(payload, '$.temperature') AS temp,
json_extract(payload, '$.status') AS status
FROM device_messages
WHERE json_extract(payload, '$.temperature') > 185.0;You can even create indexes on JSON expressions, which means querying semi-structured data from thousands of sensors doesn't have to be slow. For edge applications where you're collecting data from devices that don't all speak the same schema — which is basically every brownfield plant — this is genuinely powerful.
Feature 3: Full-text search with FTS5
Need to search through maintenance logs, operator notes, alarm descriptions, or work order histories on a local system? SQLite's FTS5 extension turns it into a capable search engine without bolting on Elasticsearch or any external service:
CREATE VIRTUAL TABLE maintenance_logs USING fts5(
equipment_id,
description,
technician_notes,
tokenize = "porter"
);The porter tokenizer handles stemming — so searching for "vibrating" also matches "vibration" and "vibrate." For a maintenance team searching through years of work orders on a local terminal, this is the difference between "scroll through 10,000 records" and "find what you need in milliseconds."
Feature 4: WAL mode — concurrent reads without locking
SQLite's biggest historical limitation was concurrency. One writer blocks everything. WAL (Write-Ahead Logging) mode doesn't eliminate that entirely, but it dramatically improves the situation:
PRAGMA journal_mode=WAL;With WAL enabled, readers never block writers and writers never block readers. Your data collection process can be writing sensor data while your dashboard reads from the same database simultaneously. On modern NVMe storage (the kind increasingly common in industrial edge PCs), SQLite in WAL mode can handle 10,000-50,000 writes per second. That's more than enough for most edge data collection scenarios.
Feature 5: Generated columns — derived data without application logic
Generated columns let you compute values automatically based on other columns, keeping derived data close to the source:
CREATE TABLE production_runs (
id INTEGER PRIMARY KEY,
start_time TEXT NOT NULL,
end_time TEXT NOT NULL,
units_produced INTEGER NOT NULL,
run_hours REAL GENERATED ALWAYS AS (
(julianday(end_time) - julianday(start_time)) * 24
) STORED,
units_per_hour REAL GENERATED ALWAYS AS (
units_produced / ((julianday(end_time) - julianday(start_time)) * 24)
) STORED
);Every insert automatically calculates run duration and throughput rate. No application code required. You can index these generated columns for fast lookups, and they stay in sync automatically.
When to use it (and when not to):
SQLite is a great fit when:
- You need a local database on an edge device, HMI, or gateway
- You're building a data buffer between the plant floor and the cloud
- You want a portable data file you can copy, email, or attach to a bug report
- You're running a single-node application that controls its own writes
- You need something that works with zero configuration and zero administration
SQLite is NOT the right choice when:
- Multiple services need to write to the same database concurrently over a network
- You need role-based access control at the database level
- You're building a multi-node backend that serves hundreds of concurrent clients
- You need features like stored procedures, replication, or LISTEN/NOTIFY
The sweet spot for manufacturing? Edge and local-first applications. The data collector running on your gateway. The local historian buffer that syncs upstream. The maintenance log that works even when the network goes down. The recipe management system on the operator workstation.
The bottom line: SQLite isn't a stepping stone to a "real" database anymore. With strict typing, JSON queries, full-text search, WAL concurrency, and generated columns, it's a production-grade tool that happens to fit in a single file. For edge computing and local-first industrial applications, the most reliable technology might be the one you've been overlooking.
Read the full feature breakdown →
Learning Lens
Where to Start in Digital Transformation for Manufacturers
![]()
One of the biggest takeaways from ProveIt! End users still don’t know where to start.
Not because they’re not capable. Not because they don’t care. Because what they’re being sold and what they actually need… are nowhere close to each other right now.
You’ve probably felt this. Vendors pushing solutions. Consultants talking about AI like it’s the answer to everything. And none of it lines up with what’s actually happening on your plant floor. That’s where the gap is.
That’s why we’re doing this workshop. Watch Walker explain it below—why we’re doing it, and what you should expect. Where to Start in Digital Transformation
This is a 2-day live workshop with Walker Reynolds and Dylan DuFresne.
Day 1 is the process:
Where do you actually start? How do you identify the right problems? What does a real strategy and architecture look like?
Day 2 is the application:
We walk through it step-by-step in a simulated Value Factory. Connect → Collect → Store → Analyze → Visualize → Find Patterns → Report → Solve
Not theory. What this actually looks like when you do it.
May 12–13 | Live Online
9:00am - 1pm CDT
Early Bird — $100 off through April 10
Use code START-EARLYBIRD
Learn more ->
Byte-Sized Brilliance
The average modern web application has 1,500 dependencies. Most developers can name maybe 20 of them.
Here's a number that should keep you up at night after reading this week's newsletter: a typical JavaScript project that runs npm install pulls in between 1,000 and 1,500 packages. The developer explicitly chose maybe a few dozen. The rest? They're transitive dependencies — packages that your packages depend on, that their packages depend on, and so on, turtles all the way down.
Axios — the package that North Korean hackers compromised last week — has over 70,000 direct dependents. That means 70,000 other packages list it as a requirement. Each of those packages has its own dependents. The blast radius isn't linear. It's exponential.
Now map that to your factory. That Node-RED instance on your gateway? It has dependencies. That web-based HMI your integrator built? Dependencies. That Python script your controls engineer wrote that calls pip install requests? You guessed it — a dependency tree they've never audited and probably couldn't read if they wanted to.
Here's the kicker: a recent study by Black Duck found that 65% of organizations admitted to being victims of a software supply chain attack in the past 12 months. Not "were at risk of." Were victims of. And Datadog's State of DevSecOps report found that 50% of organizations are using third-party libraries within a single day of their release — before the community has had time to catch anything malicious.
We obsess over firewalls, air gaps, and network segmentation on the plant floor. And we should. But the code running inside those segmented networks is built on a tower of trust that extends to thousands of strangers on the internet — any one of whom might get a convincing Slack message from a fake company founder on a Sunday night.
The call isn't coming from outside the house. It's been npm installed into the foundation.

Responses