

Presented by
![]()
View in web for best experience
St. Patrick's Day is tomorrow, which means green beer, questionable decisions, and a whole lot of people claiming Irish ancestry they absolutely cannot prove.
It also means everyone's hunting for that pot of gold at the end of the rainbow. And in manufacturing right now, that pot of gold has a name: AI.
Robots that train themselves in simulation. Code that writes itself. Tools that automate the boring stuff so your engineers can focus on the hard stuff. The promise is real. The hype is also real.
But here's the part nobody at the AI conference wants to say out loud: the promise of AI doesn't mean you're ready for AI. Most manufacturers are still just trying to connect to all their machines — collecting and storing data from dozens of different systems, protocols, and vendors. Forget contextualizing that data, let alone running models on top of it. You can't build a smart factory on a data foundation that doesn't exist yet.
And even for the teams that have gotten there? More AI code doesn't automatically mean better outcomes. More robots in simulation doesn't mean they'll behave on the floor. More autonomy in your tools doesn't mean your network is ready for it. And your security architecture — however solid it looks on paper — almost certainly has blind spots your IT team doesn't know about yet.
This week we're covering a robotics breakthrough that might actually close the gap between virtual and physical, a startup betting that AI-generated code needs to be proven correct — not just tested, why the security model everyone's relying on quietly breaks down the moment it hits an OT environment, and a practical guide to running AI coding tools and agent teams safely in your own environment.
Here's what caught our attention this week:
ABB and NVIDIA Just Claimed They Closed the Biggest Gap in Industrial Robotics

For decades, getting a robot to behave in the real world the way it behaved in simulation has been one of manufacturing's most stubborn problems. You'd spend months programming a robot in virtual environments, deploy it to the floor, and then spend more months debugging why it kept missing by a few millimeters, fumbling parts, or flat-out failing when lighting conditions changed. The "sim-to-real gap" — the difference between how a robot performs in simulation versus how it performs in a real factory — has been the silent tax on every robotics deployment.
ABB and NVIDIA say they've closed it. We'll see.
The details:
ABB Robotics is integrating NVIDIA's Omniverse simulation libraries directly into RobotStudio — the platform used by more than 60,000 robotics engineers worldwide to design, program, and simulate production lines. The result is a new product called RobotStudio HyperReality, launching in the second half of 2026.
Here's the architectural argument for why this might be different from the digital twin announcements you've tuned out before:
- ABB is the only robot manufacturer whose virtual controller runs the exact same firmware as its physical hardware. That's the detail that makes a 99% simulation-to-real accuracy claim at least plausible — the simulation isn't approximating the robot's behavior, it's literally running the same code.
- NVIDIA's Omniverse handles physically accurate simulation — realistic lighting, material textures, shadows, and environmental behavior that previous tools struggled to replicate.
- ABB's Absolute Accuracy technology reduces robot positioning errors from 8–15mm down to around 0.5mm in calibrated systems.
The claimed numbers — and we're flagging these as claimed because the product isn't shipping yet:
- 80% faster setup and commissioning time
- 40% lower deployment costs (by eliminating physical prototyping)
- 50% faster time-to-market for complex products
Take those with a grain of salt until real customers report back. Vendor benchmarks have a way of looking different once your actual parts, your actual lighting, and your actual floor vibrations enter the picture.
Why it matters — if it works:
Commissioning a new robot cell today is expensive, slow, and deeply manual. You bring in an integrator, build physical prototypes, run test after test on actual hardware, and iterate until it works. That process costs weeks and hundreds of thousands of dollars — which is exactly why advanced robotics has historically been out of reach for small and mid-sized manufacturers.
If HyperReality delivers even half of what ABB is claiming, it meaningfully changes that math.
Real-world scenario:
Foxconn — the world's largest electronics contract manufacturer — is already piloting HyperReality for consumer electronics assembly. That's one of the hardest automation environments on the planet: tiny metal components, multiple device variants, and precise pick-and-place requirements that have historically demanded extensive manual debugging. It's a credible pilot customer. What Foxconn reports after full deployment will tell us a lot more than the press release.
Meanwhile, a startup called WORKR is using the same technology to bring advanced robotics to small and mid-sized U.S. manufacturers — with the goal of deploying robots that operators can set up without any programming knowledge. They're showcasing it at NVIDIA GTC this week. Bold claim. Worth watching.
The bottom line:
The sim-to-real gap is real, the architectural approach here is genuinely interesting, and the pilot customers are credible. But "launching H2 2026" means nobody outside a handful of beta sites has actually stress-tested this yet. Add it to your watchlist, not your purchase order. If the numbers hold up in production, this is a meaningful shift in how manufacturers can deploy and scale robotics. If they don't, it joins a long list of promising announcements that hit a wall when they met a real factory floor.
AI Writes Code. But Can You Trust It?
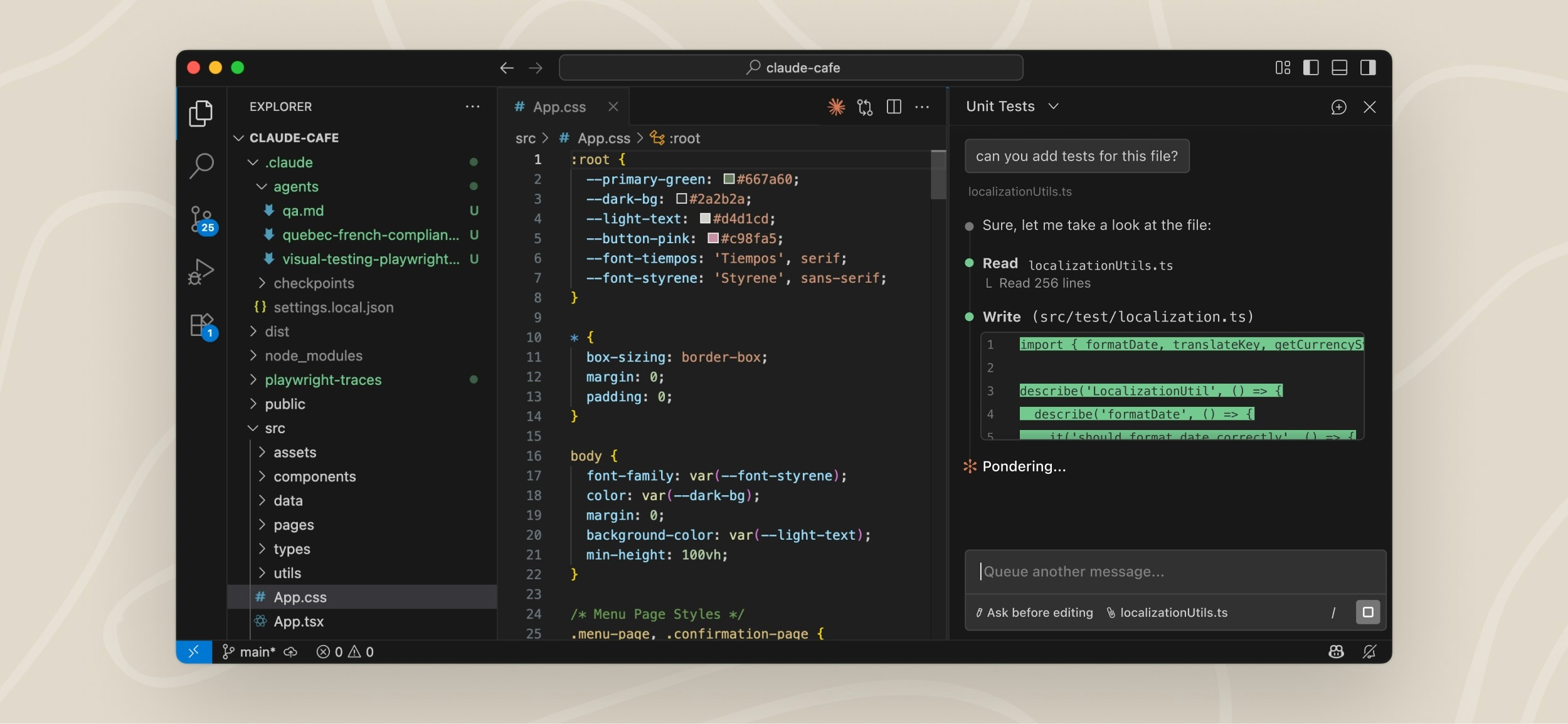
Here's a scenario playing out in engineering teams right now: a developer asks an AI coding assistant to write a script that pulls data from a PLC, formats it, and pushes it to a historian. The AI produces clean-looking code in about 30 seconds. The developer scans it, it looks right, they ship it. Six weeks later, the historian is quietly logging corrupted values — and nobody knows why.
This is the problem a Silicon Valley startup called Axiom is trying to solve. And they just raised $200 million to do it.
The details:
Axiom came out of stealth with a $200M Series A at a $1.6 billion valuation — roughly one year after founding, with about 20 employees. That's not a company building a better chatbot. That's a company that convinced serious investors the current approach to AI-generated code has a fundamental flaw.
Their argument: AI coding tools are essentially very confident guessers. They produce code that looks correct and usually runs without errors. But "runs without errors" is not the same as "provably correct." There's a meaningful gap between those two things — and in most software, that gap is tolerable. In industrial systems, it isn't.
Axiom's approach is called Verified AI. Instead of testing whether code produces the right output, they use a branch of mathematics called formal verification — specifically a programming language called Lean — to prove that every reasoning step in the code is machine-checkable and correct. Errors are caught deterministically, not statistically.
Think of the difference this way: traditional testing is like checking if a bridge holds by driving trucks across it. Formal verification is like proving mathematically that the bridge will hold before you ever build it.
Why it matters for manufacturing:
Software in most industries can afford to be "probably correct." A bug in your e-commerce checkout flow is embarrassing and costs revenue. A bug in a script managing a batch process, a safety interlock, or a pressure control loop is a different category of problem entirely.
Manufacturing teams are already using AI coding tools to write:
- OPC UA and Modbus connectivity scripts
- Data pipeline and historian integration code
- SCADA alarm logic and threshold calculations
- Reporting and OEE calculation scripts
All of these touch real physical processes. An AI-generated off-by-one error in an OEE calculation is annoying. An AI-generated logic error in a safety system is not.
The honest caveat:
Formal verification isn't new — it's been used in aerospace, medical devices, and semiconductor design for decades. The reason it hasn't gone mainstream is that it's hard and slow. Axiom's bet is that AI can now make formal verification fast enough to be practical for everyday software development. That's an ambitious claim and at a year old with 20 employees, they haven't proven it at scale yet. Watch what their customers say, not what the pitch deck says.
The bottom line:
AI-generated code isn't going away — and your engineering teams are already using it whether you have a policy about it or not. The real question isn't if AI writes code in your environment, it's whether anyone is checking that the code is actually correct. For now, that means human review, test coverage, and healthy skepticism. Axiom wants to make it mean something stronger. Keep an eye on them.
Zero Trust Doesn't Work the Way You Think It Does in OT Environments

Zero trust is the security world's favorite phrase right now. Never trust, always verify. Assume breach. Enforce least privilege. In corporate IT environments — where identity is clear, devices are managed, and network paths are well understood — it works well. Security teams have adopted it and seen real results.
But on the plant floor? Zero trust quietly breaks down. And the dangerous part is that it breaks down in ways that look fine on paper until after an incident.
First — what is Zero Trust, exactly?
Zero trust is a security model built around one core idea: don't automatically trust anything or anyone, even if they're already inside your network. Traditional security assumed that anything behind the firewall was safe. Zero trust threw that out. Every user, every device, every connection gets verified — every time.
It was built for a world of laptops, cloud apps, and human users logging into systems. That world has strong identities, manageable devices, and predictable network behavior.
Your OT environment is none of those things.
Why OT breaks all three of Zero Trust's assumptions:
Zero trust assumes that trust is explicit (you can verify who's asking), identity-centric (there's a clear identity attached to every connection), and continuously enforceable (you can check every transaction, every time). OT and IIoT systems violate all three by design:
- Visibility is incomplete by design. Devices are deployed by facilities teams, engineering groups, or third-party integrators — not your security team. Asset inventories are almost always behind reality. Many devices only communicate during specific operational states, leaving long silences that security tools misread as normal.
- Networks are functionally flat even when they look segmented. Broadcast discovery protocols, shared gateways, and centralized controllers undermine your segmentation assumptions. Two devices that never talk directly to each other can still influence each other through shared infrastructure. The diagram looks segmented. The operation isn't.
- Trust is implicit and durable. Your PLCs trust your controllers because they always have. Your controllers trust your management platform because it's "authorized." Your cloud services trust device identities baked into firmware years ago. None of these trust relationships are documented, and almost none are regularly revisited. Zero trust assumes you can challenge trust continuously. OT assumes trust persists until something breaks.
The real problem: attacks don't travel the way you think.
Here's what security teams often get wrong: they model risk based on network topology — subnets, firewall rules, DMZs, zones. That mental model works in IT. It fails in OT because attacks don't propagate through routed network paths. They travel through shared controllers, inherited firmware, update mechanisms, and management platforms — places where trust already exists and nobody's watching.
Once an attacker is inside a trusted component — a building automation system, a vendor remote access tool, a protocol gateway — they don't need to steal credentials from downstream systems. They move with the grain of the architecture. The trust does the work for them.
This is exactly what Dragos documented in their 2026 OT/ICS report: threat groups like KAMACITE and VOLTZITE aren't brute-forcing their way through firewalls. They're mapping control loops, inheriting trusted access paths, and positioning themselves for disruption weeks or months before anyone notices.
What to actually do about it:
The article's author — a Georgetown and George Washington University cybersecurity faculty member — isn't saying abandon zero trust. He's saying scope it correctly and supplement it with something OT environments actually need: trust mapping.
Instead of asking "who is allowed to talk to what?" (zero trust's question), also ask "what changes if this component fails or gets compromised?"
That means:
- Map your functional dependencies explicitly — not just network connections, but which components propagate trust across systems
- Prioritize your management planes, update mechanisms, and protocol gateways — not because they're glamorous targets, but because they're structural amplifiers. If one gets compromised, it bypasses all your downstream controls simultaneously
- Evaluate vendor risk differently — suppliers should be assessed not just on what they deliver but on how much trust they inherit and propagate once they're integrated into your environment
- Stop treating OT asset inventories as an IT problem — if your security team doesn't know what's on the floor, your zero trust model has a blind spot the size of your production line
The bottom line:
Zero trust is a good idea applied to the wrong surface in OT environments. It governs access decisions. It doesn't model how compromise actually spreads once trust already exists — and in industrial environments, trust already exists everywhere. Layering zero trust on top of an OT network without also mapping how that network actually propagates trust is like installing a great lock on the front door and leaving the factory windows open.
A Word from This Week's Sponsor
![]()
Litmus — The Infrastructure Behind Industrial AI
Last week at ProveIt!, Litmus delivered one of the most compelling demonstrations of the entire event.
As a Title Sponsor, they didn’t just talk about AI.
They demonstrated how modern industrial infrastructure becomes the foundation upon which AI-native applications can actually run.
Industrial AI doesn’t fail because of models.
It fails because of infrastructure.
Disconnected PLCs.
Fragmented OT data.
Cloud-first architectures that ignore edge reality.
That’s the gap Litmus is built to solve.
Litmus Edge is a complete edge data platform designed to simplify OT-IT data pipelines and make industrial AI possible at scale.
With 250+ industrial connectors and no-code integration, Litmus enables manufacturers to:
• Connect and process real-time OT data from virtually any system
• Contextualize and normalize data at the edge — not in post-processing
• Deploy analytics and AI with low latency and high reliability
• Scale across sites without losing governance or control
This isn’t about sending more data to the cloud.
It’s about creating structured, contextualized intelligence at the edge — where operations actually happen.
What stood out at ProveIt! was how Litmus embeds AI inside context-aware industrial architecture.
From real-time data collection to centralized management to AI deployment, the platform is built for production environments — not lab demos.
And for engineers who want to get hands-on, the Litmus Edge Developer Edition provides full platform access with a resettable license. No watered-down trial. No artificial limits.
If your organization is serious about bridging OT and IT — and building infrastructure that AI can actually depend on — Litmus is a platform worth understanding.
Want to kick the tires on Developer Edition?
Link Here: https://litmus.io/litmus-edge-developer-edition
How to Run AI Coding Tools — and Entire AI Teams — Safely
Your engineers are already using AI coding assistants. Maybe officially, maybe not. But they're using them — to write data pipeline scripts, query historians, prototype OPC UA connections, and knock out the boilerplate that used to eat half a Friday afternoon.
The problem isn't that they're using them. The problem is that most teams haven't thought through what it means to let an AI agent write and execute code in an environment connected to real industrial systems. Docker just published two practical guides that are worth your attention — because together they map directly to that problem.
First, a quick explainer — what is Docker?
Docker is a tool that lets you run software inside isolated, self-contained environments called containers. Think of a container like a sealed lunchbox — everything the software needs to run is packed inside it, and it can't mess with anything outside the box. It's widely used in software development because it solves the classic "it works on my machine" problem. If it runs in the container, it runs the same way everywhere.
That isolation property is exactly why it matters for industrial software teams running AI coding tools.
The three-layer setup — and why each layer matters:
Layer 1 — Run your AI model locally
By default, AI coding tools like Claude Code send your prompts — including your code, your file names, your system details — to a cloud API. For most software teams that's fine. For teams working on proprietary process logic, control system configurations, or anything touching production infrastructure, that's a data governance conversation you probably don't want to have after the fact.
Docker's Model Runner lets you run an AI model entirely on your local machine, with zero data leaving your environment. Same experience, full data control, no cloud dependency.
Layer 2 — Connect your AI agent to real tools safely
An AI coding assistant that can only see the file you're working on is useful. One that can query your git history, read your codebase, check your Jira backlog, and cross-reference your documentation is genuinely powerful.
Docker's MCP Toolkit gives Claude Code access to 300+ pre-built, containerized tool integrations — GitHub, Jira, local filesystems, databases, and more — with one-click deployment and automatic credential handling. MCP stands for Model Context Protocol, which is fast becoming the standard way AI agents connect to external tools and data sources. Think of it as USB-C for AI integrations: one standard connector, works with everything.
Layer 3 — Safe autonomous execution via Docker Sandboxes
This is the one that matters most for industrial environments. As AI coding agents get more capable, they don't just suggest code — they install packages, modify files, run commands, and make changes autonomously. That's powerful. It's also exactly the kind of behavior you don't want running unconstrained on a workstation connected to your OT network.
Docker Sandboxes solve this by running the AI agent inside a disposable microVM — a fully isolated virtual machine with no access to your host machine. The agent can install whatever it wants, modify whatever files it wants, even delete things — and none of it touches your actual system. When the task is done, throw away the sandbox. Your machine is exactly as you left it.
Now — take it one step further: AI teams, not just AI tools
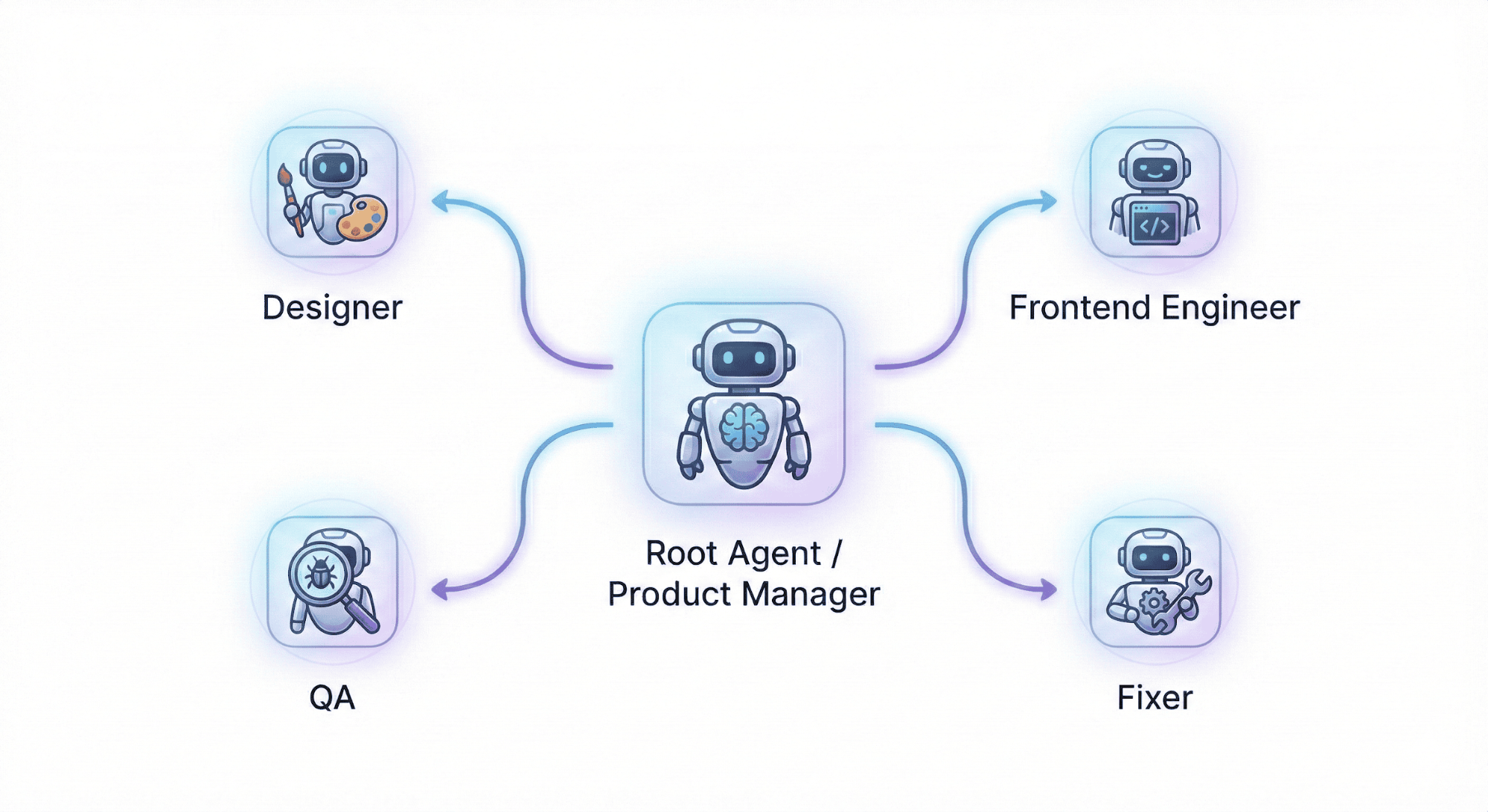
Here's where it gets genuinely interesting. Docker's second guide introduces Docker Agent — an open source framework for running not just one AI coding assistant, but an entire team of specialized AI agents working together.
Think of it like this. Right now, a single AI agent is doing everything: writing the code, figuring out the architecture, testing it, and fixing bugs — context-switching constantly just like an overworked junior engineer. Docker Agent lets you instead define a team:
- A product manager agent that breaks requirements into tasks and coordinates the team
- A designer agent focused purely on UI specifications and wireframes
- An engineer agent that implements the code
- A QA agent that runs tests and identifies bugs
- A fixer agent that resolves what QA flags
Each agent has its own role, its own model, its own set of tools, and its own instructions. The root agent coordinates. The others execute. And the whole team runs autonomously inside a Docker Sandbox — so even if an agent makes a catastrophic decision, it's contained inside a microVM and can't touch your host machine or anything connected to it.
The manufacturing angle:
Here's how this plays out on the plant floor. Your controls engineer needs a Python script that pulls temperature data from a Modbus device, converts units, and pushes it to your historian via REST API. With a sandboxed AI team, they describe the goal — the engineer agent writes the code, the QA agent tests it against edge cases, the fixer agent handles the timeout handling that the first version missed. All of it happens in an isolated environment. The human reviews the output, validates it, and makes the call to deploy.
The AI did the heavy lifting in a safe box. The human made the decision to ship.
This matters because the risk profile in industrial software is different. A bug in a web app means a bad user experience. A bug in a script managing batch records, pressure calculations, or safety interlocks means something else entirely. The sandbox architecture doesn't eliminate that risk — but it puts a hard wall between "AI experimentation" and "things connected to your production network."
The honest caveats:
Docker Sandboxes and Docker Agent are still experimental — both are moving fast and breaking changes happen between versions. MicroVM sandboxes currently require macOS or Windows; Linux users get container-based isolation instead. And this is Docker's ecosystem, so naturally they're promoting their own toolchain. Other approaches to sandboxed AI execution exist. But the underlying architecture — local models, isolated tool access, microVM execution boundaries — is sound regardless of which tools you use to implement it.
The bottom line:
AI coding tools are coming to industrial software environments whether your security policy is ready for them or not. The question is whether your team uses them with guardrails or without. Local model execution keeps your data on-prem. MCP integrations give agents useful context without blanket system access. Sandboxed microVM execution means an autonomous agent can't make a mess of a machine connected to your production network. That's not a perfect solution — but it's a responsible starting point.
Run Claude Code with Docker → | Build AI Agent Teams →
Byte-Sized Brilliance
Amazon S3 turned 20 years old this week. When it launched in 2006, it stored 1 petabyte of data across 400 nodes. Today it holds over 500 trillion objects and handles 200 million requests per second across hundreds of exabytes of data.
To put that in perspective: if every one of those 500 trillion objects were a grain of sand, you'd have enough sand to fill roughly 200 Great Pyramids of Giza. Twice.
Here's the part that should make every manufacturer uncomfortable: AWS reduced S3's price by 85% over those 20 years — from 15 cents per gigabyte down to just over 2 cents — while maintaining complete backward compatibility with code written two decades ago. Every application built on S3 in 2006 still works on S3 today, without a single change.
Now think about your historian. Your SCADA system. Your MES. How many of those have broken integrations, forced migrations, or stranded data because a vendor changed their API, dropped a protocol, or got acquired and sunset the product?
S3's secret wasn't just cheap storage. It was ruthless backward compatibility and relentless cost reduction — two principles that industrial software vendors have historically treated as optional. The result is that S3 became the default foundation for an entire generation of applications, including, increasingly, AI and machine learning workloads built on top of decades of stored data.
The lesson for manufacturers isn't "use S3." It's: the data infrastructure you choose today will either compound in value or compound in technical debt over the next 20 years. Proprietary historians, locked data formats, and vendor-controlled APIs are the opposite of S3. Open standards, portable formats, and interoperable architectures are the same bet AWS made in 2006 — and it paid off at a scale nobody predicted.
Your process data is worth something. Make sure you own it.
|
|
|
|
|
|

Responses