

Presented by
![]()
Happy March 9th, Industry 4.0! Well... "happy" might be generous. You look tired. We're all tired.
You lost an hour this weekend to daylight saving time. In 2026. We can land rockets on drone ships, generate photorealistic video from a text prompt, and run AI agents that autonomously manage supply chains — but we still can't stop Congress from stealing an hour of sleep from us (and then giving it back in the fall) for a policy that was designed to save candle wax. If you ever want proof that legacy systems are the hardest things to kill, look no further than your clock.
Speaking of legacy systems that refuse to die — let's talk about AI pilots. MIT says 95% of generative AI pilots never make it to production. Manufacturing's failure rate sits at 76%. And the biggest culprit isn't the technology — it's messy workflows, siloed data, and executives who lose interest six months in.
This week's issue is an AI reality check. We're looking at why pilots stall, what specific mistakes manufacturers keep making, why the code your AI writes might look perfect but perform terribly, and what China is doing while we're still debating whether to fund Phase 2.
It's not a doom-and-gloom issue. It's a "let's stop repeating the same mistakes" issue. Every article this week comes with something you can actually do about it.
Here's what caught our attention:
The Prototype Mirage: Why 95% of AI Pilots Never Make It to Production

Here's a number that should make every plant manager sit up: 95% of generative AI pilots fail to reach production. That's not a typo — that's MIT. And manufacturing specifically? A 76.4% failure rate, with average sunk costs of $4.2 million per abandoned project.
But here's the thing — the technology usually works. The demos are impressive. The proof-of-concept nails it. Then reality hits.
So what's actually killing these pilots?
Researchers are calling it the "Prototype Mirage" — a phenomenon where companies measure success based on how good the demo looks, only to watch it collapse in production due to reliability issues, runaway costs, and a fundamental lack of trust in the output.
The pattern looks like this:
- The demo dazzles. An AI agent processes intake forms, predicts equipment failures, or generates reports. Leadership sees it and says "ship it."
- Production breaks it. The agent that worked on clean demo data can't handle the messy, stateful, constantly-shifting reality of your actual operations. Errors compound with every step — researchers call this "stochastic decay."
- Nobody knows why. 73% of failed projects lack clear metrics for success. You can't fix what you can't measure.
- The sponsor moves on. 56% of AI projects lose active C-suite sponsorship within six months. No champion, no budget, no Phase 2.
Why this hits manufacturing harder than most:
Your factory floor isn't a clean API. It's decades of legacy PLCs, proprietary SCADA systems, custom ERP configurations, and tribal knowledge that lives in the heads of operators who are retiring. When an AI agent built on clean training data meets your actual OT environment — with its inconsistent naming conventions, miscalibrated sensors, and missing metadata — the model doesn't just underperform. It hallucinates. It gives you flawed demand forecasts. It recommends maintenance schedules that don't account for your actual production constraints.
Real-world scenario: Your quality team deploys an AI-powered defect detection system. It works beautifully in the pilot on Line 1 — 98% accuracy, catches things human inspectors miss. Then you try to roll it to Line 3, which runs a different product mix, different lighting conditions, and sensors that haven't been recalibrated since 2019. Accuracy drops to 61%. The operators stop trusting it. Usage flatlines. Six months later, someone asks "whatever happened to that AI thing?"
Sound familiar?
What actually works — the 20% that succeed:
The projects that make it share a few patterns:
- Clear, pre-approved success metrics. Projects with defined KPIs before launch succeed at 54% vs. 12% without. Don't start a pilot without knowing exactly what "success" means in production — not just in the demo.
- Sustained executive sponsorship. 68% success rate with active C-suite involvement vs. 11% without. Someone has to keep fighting for budget when the initial excitement fades.
- Treat it as transformation, not a tech project. 61% success rate when treated as organizational change vs. 18% when treated as an IT initiative. The technology is the easy part. The hard part is getting your maintenance supervisor to actually use the dashboard.
- Start with your data, not the model. If your data is siloed, inconsistent, or incomplete, no amount of AI sophistication will save you. Fix the plumbing first.
The bottom line: The AI isn't broken — your implementation strategy is. Stop chasing impressive demos and start building the boring foundation: clean data, clear metrics, executive buy-in that lasts longer than a quarter, and a realistic plan for what happens when your pilot meets the chaos of real operations.
8 AI Integration Mistakes That Keep Stalling Manufacturing ROI

So if 76% of manufacturing AI projects fail (see above), what specifically is going wrong? Manufacturing Today broke it down into eight patterns — and if you've been through an AI pilot at your plant, you're going to recognize at least half of these immediately.
Mistake #1: Automating a broken process.
This is the big one. Over half of manufacturers still cite outdated manual systems as their biggest hurdle — and then they try to layer AI on top of them. Here's the problem: if your process is already inefficient, AI just helps you produce waste faster. You don't get optimization. You get accelerated dysfunction.
Real-world scenario: Your team deploys an AI-driven scheduling system on a production line that still relies on spreadsheet-based shift handoffs. The AI optimizes the schedule beautifully — but the handoff notes never make it into the system, so the night shift runs the wrong batch anyway. The AI did its job. Your process didn't.
The fix: Before you bring AI anywhere near a workflow, map it. Document it. Find the bottlenecks that exist without AI. Fix those first. Then automate.
Mistake #2: Neglecting data hygiene and context.
This one is painfully familiar. Your factory floor data (OT) is disconnected from your enterprise systems (IT). Different naming conventions. Miscalibrated sensors. Missing metadata. Without context, your AI doesn't produce insights — it produces hallucinations with extra steps.
Translation: Your AI is trying to predict equipment failures using vibration data from the PLC, but it can't cross-reference that with the maintenance work orders in your ERP or the production schedule in your MES. Without that full picture, the prediction is just a guess in a fancy dashboard.
The fix: This is where a Unified Namespace (UNS) architecture earns its keep. A UNS creates a single access point for all your operational and enterprise data — structured, contextualized, and available in real time. It's not glamorous. It's plumbing. But it's the plumbing that makes everything else work.
Mistake #3: Pursuing moonshot projects instead of incremental wins.
FOMO is real — even on the plant floor. The temptation is to launch a massive, organization-wide AI transformation that's going to "revolutionize everything." These projects almost always collapse under their own weight. They're too complex, too expensive, and too slow to show value before leadership loses patience.
The fix: Start small. Pick one line, one process, one problem. Prove value. Then scale. The companies that escape pilot purgatory aren't the ones with the biggest ambitions — they're the ones with the smallest, most disciplined starting points.
Mistake #4: Overlooking the human in the loop.
Here's the uncomfortable truth: 65% of workers are anxious about AI replacing their jobs. When you ask your maintenance team to train an AI system on their expertise, they're not stupid — they know what that could mean. And 86% of employees say AI outputs often need revision.
You can build the most technically brilliant predictive maintenance system in the world. If your operators don't trust it, they won't use it. Worse, they'll build shadow workarounds that bypass it entirely. Usage flatlines. The project gets shelved.
The fix: Involve your operators from Day 1 — not as users, but as co-designers. Let the maintenance supervisor who's been listening to that press for 20 years help define what "abnormal" sounds like. The AI is their tool, not their replacement.
Mistake #5: Managing AI like traditional software.
Traditional software is deterministic — same input, same output, every time. AI is probabilistic. It drifts. Machine conditions change, raw material quality fluctuates, seasonal patterns shift. That model you trained six months ago? It's slowly getting dumber, and nobody's watching.
The fix: AI models need continuous monitoring and recalibration. Build a feedback loop. Schedule regular model performance reviews the same way you'd schedule preventive maintenance on a motor. Because that's exactly what this is — maintenance on a digital asset.
Mistake #6: Ignoring cybersecurity in the OT/IT convergence.
This one should terrify you. As AI connects factory floor sensors to cloud analytics, your attack surface expands dramatically. Legacy OT systems were designed for reliability, not security — and now they're connected to networks that bad actors are actively targeting. (If you want a preview of what that looks like, look at the Dragos 2026 OT Cybersecurity Report — ransomware groups targeting manufacturing surged 49% last year.)
The fix: Treat OT cybersecurity as a prerequisite for AI deployment, not an afterthought. Segment your networks. Enforce multi-factor authentication on edge devices. And for the love of uptime, don't expose management interfaces to the internet.
Mistake #7: Failing to define measurable business KPIs.
"We need AI because our competitors have AI" is not a strategy. If you can't articulate what success looks like before you start spending money, you're going to end up measuring adoption instead of impact. Projects with clearly defined KPIs before launch succeed at 4.5x the rate of those without.
The fix: Define success in operational terms your CFO cares about: reduction in unplanned downtime, scrap rate improvement, energy cost savings, OEE gains. Not "we trained a model" — "we reduced Line 4 downtime by 18% in Q2."
Mistake #8: Underestimating the total cost of ownership.
The platform license is the tip of the iceberg. Nobody budgets for the new sensors you'll need, the edge computing hardware, the high-speed networking upgrades, the data engineers to maintain the pipeline, or the ongoing model retraining. The result: projects that are technically successful but economically unsustainable.
The fix: Budget for the full lifecycle — not just Year 1. Include infrastructure, talent, training, maintenance, and the inevitable "we didn't think of that" line item. If the TCO math doesn't work at scale, it doesn't matter how good the demo was.
Why it all matters:
Here's what ties all eight mistakes together: none of them are about the AI being bad. The algorithms work. The models are capable. The failure is organizational, architectural, and cultural. It's messy data, siloed systems, missing buy-in, absent metrics, and budgets that only account for the fun part.
If you're planning an AI initiative in 2026, don't start with "which model should we use?" Start with "is our data clean, is our process documented, do our operators trust the system, does our leadership know what success looks like, and can we afford this thing in Year 3?"
The bottom line: AI in manufacturing fails when it's treated like a technology purchase instead of an operational transformation. The 24% that succeed aren't using better models — they're doing the boring work of fixing their data, aligning their teams, and defining success before they write a single line of code.
China's New Five-Year Plan Is Betting Everything on AI-Driven Manufacturing

While American manufacturers are debating whether to fund AI Phase 2, China just published a national plan that mentions AI dozens of times and commits to an "AI+ action plan" across the entire economy. Manufacturing, healthcare, education — AI isn't a department initiative over there. It's national infrastructure.
What's in the plan:
China's latest Five-Year Plan lays out an aggressive strategy to embed AI across every major sector, with manufacturing getting top billing. The key pillars include massive investment in computing infrastructure to fuel AI development, an explicit push toward open-source AI ecosystems (think: state-backed alternatives to the tools you're using today), and a coordinated national effort to close the technology gap with the United States.
This isn't aspirational language buried in a white paper. It's a funded, coordinated, top-down mandate with timelines and accountability.
Now, a reality check on the plan itself:
Before we panic, let's acknowledge something: China has a long history of announcing ambitious tech mandates that look better on paper than they do on the factory floor. The "Made in China 2025" plan promised semiconductor self-sufficiency and world-leading smart manufacturing by — well, 2025. That didn't quite land as advertised. China still relies heavily on Western chip designs, ASML lithography machines, and imported industrial automation software.
And here's the irony that should jump off the page for anyone who's lived through a digital transformation initiative: China's top-down, mandate-driven approach to AI adoption mirrors exactly the pattern that fails inside U.S. companies. Remember Mistake #3 from the article above? The moonshot project that collapses under its own weight because leadership mandated it from the boardroom instead of building it from the plant floor?
We've spent the last decade learning — painfully — that digital transformation doesn't work when the C-suite decrees "we're an AI company now" and expects the shop floor to figure it out. The projects that actually survive are bottom-up: driven by operators and engineers who identify real problems, with executive support clearing the path and signing the checks. Not the other way around.
China is essentially running the world's largest top-down digital transformation. Government says "do AI." Factories comply. Reports go up the chain saying it's working. But anyone who's watched a plant manager nod along in a corporate digital strategy meeting while mentally planning to keep running things the old way knows how this story usually ends. Top-down mandates are great at generating dashboards. They're terrible at generating actual change on the floor.
There's also the talent question. China has invested heavily in AI education, but it's experiencing significant brain drain among its top AI researchers — many of whom have left for opportunities in the U.S. and Europe. And the recent exodus from companies like Alibaba's Qwen team (which your TLDR newsletters covered just last week) suggests the internal talent picture is more complicated than the five-year plan implies.
So should you ignore it? Absolutely not.
Skepticism about execution doesn't mean the competitive pressure isn't real. Even if China delivers on half of this plan, the implications are significant. Here's why:
1. Your competition isn't just the plant across town anymore. Chinese manufacturers are getting state-backed AI infrastructure — subsidized computing, national data standards, coordinated research pipelines — while most U.S. manufacturers are still fighting for budget to connect their PLCs to a historian. Even imperfect execution of a national AI strategy, at China's scale, creates cost and speed advantages that compound over time.
2. The open-source AI push changes the tooling landscape. China is investing heavily in building its own open-source AI ecosystems. That means more tools, more models, and more frameworks entering the global market — some of which will be genuinely useful, and some of which will come with supply chain risks your security team should be thinking about. (Remember CyberStrikeAI? That AI-powered attack tool with ties to China's Ministry of State Security that compromised 600+ Fortinet firewalls? The line between "open-source AI tools" and "state-sponsored capability building" is getting blurrier by the month.)
3. The talent war is global now. Despite the brain drain, China is still graduating more STEM students annually than any other country. Meanwhile, U.S. manufacturing is facing a "silver tsunami" of retirements and struggling to attract workers who'd rather write code in a hoodie than troubleshoot a VFD in steel-toes. The manufacturers who figure out how to use AI to capture institutional knowledge — the stuff that lives in the heads of your retiring operators — will have a structural advantage over those who don't.
What U.S. manufacturers should actually do about this:
Let's be clear — nobody's suggesting you need to match China's national AI strategy from your plant in Ohio. But there are practical takeaways:
- Stop treating AI as optional. The competitive pressure isn't theoretical anymore. Even a partially-executed national AI strategy from the world's largest manufacturing economy changes the playing field. "We'll get to it next year" is getting more expensive every quarter.
- Invest in your data foundation now. China's real advantage isn't smarter algorithms — it's coordinated data infrastructure. You can build your own version of that at the plant level. Clean data, connected systems, a Unified Namespace that gives every application a single source of truth. That's your competitive moat.
- Take supply chain security seriously. As AI tools proliferate globally, know where your software comes from. Audit your dependencies. Understand the difference between a community-maintained open-source project and a state-adjacent tool that happens to be free.
- Capture institutional knowledge before it walks out the door. That 30-year maintenance veteran who can diagnose a bearing failure by sound? Document what they know. Build it into your training systems. Use AI to augment the next generation, not replace the current one.
The bottom line: China's plan is ambitious, probably overambitious, and will almost certainly underdeliver on its own timeline. Sound familiar? It should — it's the same pattern we see in every top-down transformation initiative, just at national scale. But underdelivering on a massive plan still moves the needle. U.S. manufacturers don't need to copy the playbook — but the ones still waiting for permission to start are going to find themselves competing against plants that never stopped, even if those plants aren't as far along as Beijing claims.
A Word from This Week's Sponsor
![]()
Litmus — The Infrastructure Behind Industrial AI
Last week at ProveIt!, Litmus delivered one of the most compelling demonstrations of the entire event.
As a Title Sponsor, they didn’t just talk about AI.
They demonstrated how modern industrial infrastructure becomes the foundation upon which AI-native applications can actually run.
Industrial AI doesn’t fail because of models.
It fails because of infrastructure.
Disconnected PLCs.
Fragmented OT data.
Cloud-first architectures that ignore edge reality.
That’s the gap Litmus is built to solve.
Litmus Edge is a complete edge data platform designed to simplify OT-IT data pipelines and make industrial AI possible at scale.
With 250+ industrial connectors and no-code integration, Litmus enables manufacturers to:
• Connect and process real-time OT data from virtually any system
• Contextualize and normalize data at the edge — not in post-processing
• Deploy analytics and AI with low latency and high reliability
• Scale across sites without losing governance or control
This isn’t about sending more data to the cloud.
It’s about creating structured, contextualized intelligence at the edge — where operations actually happen.
What stood out at ProveIt! was how Litmus embeds AI inside context-aware industrial architecture.
From real-time data collection to centralized management to AI deployment, the platform is built for production environments — not lab demos.
And for engineers who want to get hands-on, the Litmus Edge Developer Edition provides full platform access with a resettable license. No watered-down trial. No artificial limits.
If your organization is serious about bridging OT and IT — and building infrastructure that AI can actually depend on — Litmus is a platform worth understanding.
Want to kick the tires on Developer Edition?
Link Here: https://litmus.io/litmus-edge-developer-edition
Your LLM Doesn't Write Correct Code. It Writes Plausible Code. Here's Why That Should Terrify Your Plant.
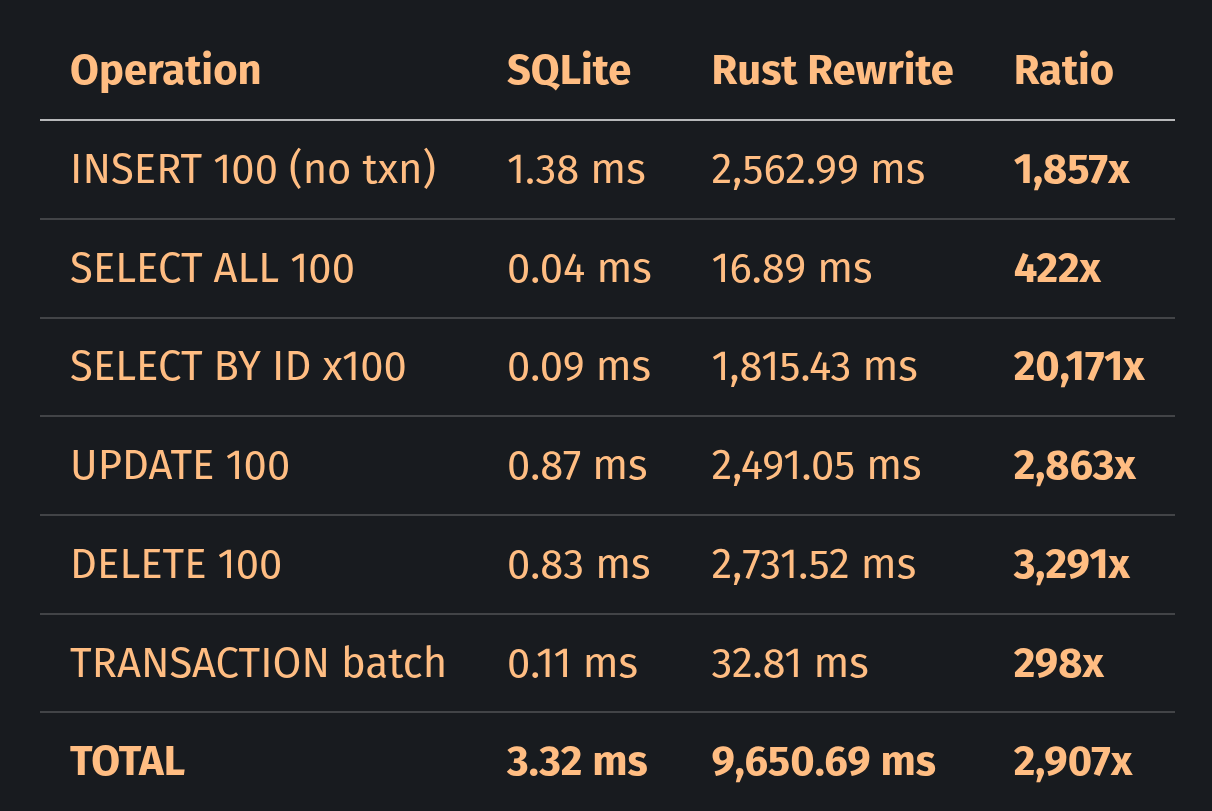
We've spent this entire issue talking about why AI initiatives fail at the organizational level — bad data, broken processes, absent leadership. But here's a failure mode nobody's talking about enough: the code your AI writes might look perfectly fine and be fundamentally wrong.
A developer recently benchmarked an LLM-generated Rust rewrite of SQLite — one of the most widely-used databases on earth. The AI-generated version compiled cleanly. It ran. It returned results. It looked correct.
It was 20,171 times slower on basic primary key lookups.
Not 20% slower. Not twice as slow. Twenty thousand times slower. The query planner the LLM wrote never checked a critical optimization flag, so every single query went through a full table scan instead of using the B-tree index. That's like having a filing cabinet sorted alphabetically and choosing to read every single folder from front to back every time someone asks for the letter "M."
How does this happen?
LLMs don't understand code the way an engineer does. They don't reason about architecture, performance trade-offs, or system-level implications. They predict the most plausible next token based on patterns in their training data. The result is code that looks right — it follows conventions, it compiles, it handles the obvious cases — but misses the deep structural decisions that separate working software from production-grade software.
Here's another example from the same research: an LLM was asked to build a disk cleanup utility. It generated 82,000 lines of code complete with a Bayesian scoring engine and a PID controller. The problem? A one-line cron job already does the same thing. The LLM didn't over-engineer it because it was trying to be clever. It over-engineered it because "plausible disk cleanup code" in its training data includes sophisticated patterns from complex systems. It pattern-matched its way to a solution that was technically impressive and practically absurd.
The kicker? A study from METR with 16 experienced open-source developers found that developers using AI assistance were actually 19% slower at completing tasks — while believing they were 20% faster. The confidence gap is the real danger. You don't just get bad code. You get bad code that everyone thinks is good code.
Why this matters on the factory floor:
You might be thinking, "I'm not rewriting SQLite. I'm building a dashboard." Fair. But think about what's actually happening in manufacturing environments right now:
- Maintenance teams are using AI to generate Python scripts that pull data from historians, calculate OEE, or trigger alerts based on sensor thresholds. If the AI writes a query that scans every record instead of using an index, your "real-time" dashboard updates every 45 minutes instead of every 5 seconds. Nobody notices until someone asks why the alert fired an hour late.
- Engineers are using AI to generate PLC logic and ladder diagrams. The code compiles. The simulation runs. But the AI doesn't understand your specific safety interlocks, your machine's actual timing requirements, or the edge case where Conveyor 3 jams and the upstream press doesn't stop because the logic assumed a condition that's only true 99% of the time. That 1%? That's how someone gets hurt.
- Data engineers are using AI to build ETL pipelines that move data from your MQTT broker into your time-series database. The pipeline works in testing with 100 messages per second. In production, your broker is pushing 10,000 messages per second and the AI-generated code doesn't handle backpressure. Data starts dropping silently. Your predictive maintenance model trains on incomplete data. Its predictions degrade. Nobody connects the dots for six months.
Real-world scenario: Your controls engineer asks an AI to write a script that monitors vibration data and flags anomalies. The AI generates clean, well-commented Python code. It even includes a nice visualization. But the threshold logic uses a static baseline instead of a rolling average, and the sampling rate doesn't account for the machine's actual RPM range. The script runs for weeks. It never flags anything. Everyone assumes the machine is healthy. Then the bearing fails catastrophically on a Tuesday morning and takes the whole line down for three days.
The code looked right. It compiled. It ran. It just didn't work.
What to actually do about this:
This isn't an "AI is bad, don't use it" article. AI-generated code can absolutely save time and reduce tedious boilerplate work. But you need guardrails:
- Never deploy AI-generated code without human review by someone who understands the domain. Not just "does it compile" — does it handle the edge cases that matter in your environment? The AI doesn't know about the quirk on Line 4 where the temperature sensor reads 3 degrees high when ambient humidity exceeds 80%.
- Test with production-scale data, not demo data. The script that works beautifully with 100 rows will behave very differently with 10 million rows. Test at the volume and velocity your actual systems produce.
- Benchmark performance, don't assume it. If the AI wrote a database query, run an EXPLAIN plan. If it wrote a data pipeline, load test it. If it wrote control logic, simulate the failure modes — not just the happy path.
- Treat AI-generated code as a first draft, not a finished product. The best use of AI in coding isn't "write me a solution." It's "write me a starting point that I'm going to review, test, and improve." The human expertise is still the critical layer between plausible code and production-grade code.
- Be especially skeptical of AI-generated code that looks impressive. Remember the 82,000-line disk cleanup utility. Complexity isn't a sign of quality — it's often a sign that the AI pattern-matched its way past the simple, correct answer.
The bottom line: AI doesn't write correct code. It writes code that looks correct — and that distinction matters a lot more when the code is running your factory than when it's running a web app. Use AI to write code faster. Then use your brain to make sure it actually works.
Byte-Sized Brilliance
Right now, 10,000 baby boomers retire every single day in the United States. In manufacturing specifically, 26% of the workforce is expected to retire by 2030 — that's over 1.5 million roles walking out the door. And here's the number that should keep you up at night: 97% of manufacturing firms say they're concerned about the brain drain. Nearly half say they're "very concerned."
But here's what makes it worse. Poor knowledge transfer costs large manufacturers an estimated $47 million per year — not in lost productivity from open headcount, but in wasted time, repeated mistakes, delayed projects, and re-learning things that somebody already figured out a decade ago. That maintenance tech who can diagnose a failing gearbox by the way it sounds at 2,400 RPM? When she retires next April, that knowledge doesn't show up in your CMMS. It doesn't live in your SOP binder. It just... disappears.
And yet, we just spent four articles talking about AI pilots that can't get out of Phase 1, code that looks right but isn't, and national AI strategies that may never deliver. Meanwhile, the most valuable dataset in your entire plant — the institutional knowledge in the heads of your most experienced operators — is being permanently deleted at a rate of 10,000 records per day, and most companies don't even have a backup strategy.
The irony is thick: we're spending millions on AI that hallucinates, while the humans who never hallucinate are quietly cleaning out their lockers.
|
|
|
|
|
|

Responses